急速に進化し続ける生成AIおよび大規模言語モデル(LLM)の世界では、より高度で精度の高い情報取得を実現するためのアプローチとして「RAG(Retrieval-Augmented Generation)」が注目を集めています。RAGは、単純にモデルに学習させた情報だけでなく、外部データをリアルタイムに取得して活用することにより、より正確かつ信頼性の高い応答を生成する技術です。
この記事では、AWSが提案するサーバーレスアーキテクチャを活用した、セキュアでスケーラブルなRAGアプリケーションの構築方法について解説しています。特に、AWS上のデータレイクとそれに連携するAI/MLサービスの組み合わせにより、企業はコスト効率よく、安全に、そして高性能な生成AIアプリケーションを設計・構築できる点に焦点を当てていきます。
RAG(Retrieval-Augmented Generation)とは
まず、RAGの基本的な概念を押さえておきましょう。RAGとは、「情報検索」と「応答生成」の2つのプロセスを統合したアプローチです。一般的な大規模言語モデルは、事前に学習した知識をもとに応答を生成しますが、知識が最新でなかったり、特定のドメインに関する情報が不足していたりする場合があります。
そこで、最新の文書や社内の特定情報を応答に活かすために、RAGではユーザーからの質問に対して以下のステップを経て応答を生成します。
1. ユーザーからの問い合わせを受け取る
2. 問い合わせに関連する情報(文書、レコードなど)を検索する
3. 検索結果をプロンプトの一部として言語モデルに渡す
4. 検索結果を参照しながら最終的な出力を生成する
このように、RAGはモデル内の知識ベースと外部の情報源を統合することで、柔軟で信頼性の高いAIアプリケーションを実現する鍵となります。
企業にとっての課題:セキュリティとスケーラビリティ
RAGのポテンシャルが広く認知される一方で、企業が実際にRAGアプリケーションを導入・運用する際には複数の課題が存在します。その代表的なものが、「セキュリティ」と「スケーラビリティ」です。
社内の重要なビジネス文書や顧客データなど、機密性の高い情報をLLMに取り込む以上、その情報が不適切にアクセスされないように堅牢なアクセス管理が求められます。また、業務やシチュエーションによって急激にトラフィックが増加する可能性がある場合、高いスケーラビリティを確保することでシステムの応答速度や信頼性を維持する必要があります。
これらの課題を同時にクリアにするソリューションとして、AWSが提案するサーバーレスデータレイクの活用が有効です。
AWSによるサーバーレス型データレイクとRAGの融合
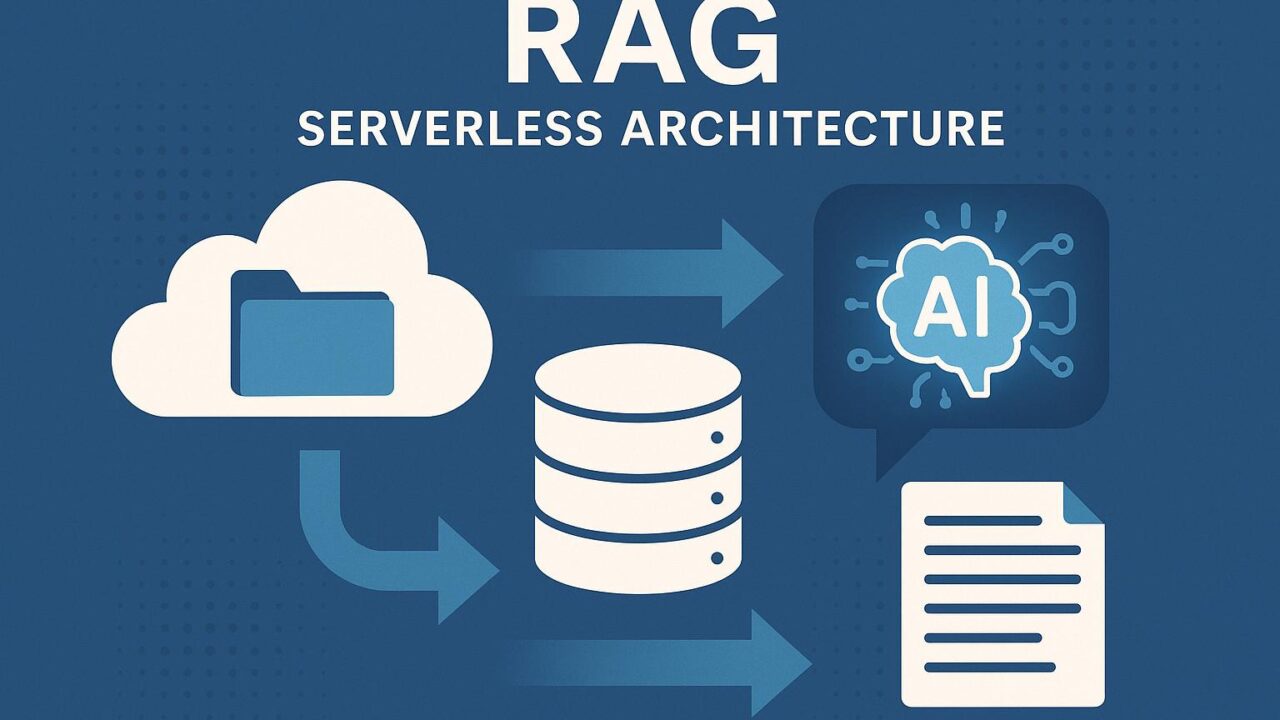
AWSでは、セキュアで費用対効果の高いRAGアプリケーションを容易に開発できるよう、複数のマネージドサービスによって構成されるサーバーレスデータレイクアーキテクチャを提供しています。
このアーキテクチャにおいて中核的な役割を果たすのが、以下の主要コンポーネントです。
1. Amazon S3:データレイクストレージ
大規模な文書群や業務データなどを格納するためのストレージとしてAmazon S3が利用されます。S3ではバケットポリシーや暗号化設定を活用することで、データのセキュリティも徹底されます。
2. AWS Glue:データカタログと変換
アップロードされた文書データを構造的に管理するために、AWS GlueによるETL(Extract, Transform, Load)処理やデータカタログの構築が行われます。これにより、非構造化データを抽出し、インデックス化が容易になります。
3. Amazon OpenSearch Serverless:検索エンジン
文書検索のためのインデクシングと高速検索を可能にするのが、Amazon OpenSearch Serverlessです。ユーザーの問い合わせに対して適切なコンテキスト文書を素早く抽出するのに最適です。Serverlessオプションを利用すれば、トラフィックに応じた自動スケーリングが可能になり、安定した性能が確保されます。
4. Amazon Bedrock(もしくはSageMaker):LLMの推論と統合
OpenAI、Anthropic、AI21などの様々なLLMプロバイダーのモデルを統合的に利用できるAmazon Bedrockを活用することで、プロンプトと検索結果を渡し、最終的な出力を生成します。さらにAmazon SageMakerを使用すれば、独自ファインチューンしたモデルのホスティングも可能です。
構築されたワークフローの一例
1. ユーザーが自然言語で問い合わせを投げる(例:「このプロフェッショナルサービスの価格モデルを教えてください」)
2. クエリ内容はAmazon API Gateway経由でAmazon Lambdaへ送信される
3. Lambda関数内で、まずOpenSearch Serverlessを使ってS3に保存されているドキュメントから関連情報を検索
4. 検索結果と元のクエリを統合し、Amazon Bedrockへ送信
5. Bedrockはそれらをプロンプトとして受け取り、LLMによって自然な応答文を生成
6. Lambdaを通じて応答が返され、ユーザーに提示
これらすべてのプロセスが完全自動で、かつ弾力的にスケーラブルであることが、AWSサーバーレスアーキテクチャの強みです。
セキュリティ強化のポイント
生成AIに機密情報を取り扱わせる際には、以下のようなセキュリティ制御が不可欠になります。
– S3暗号化とIAMロールベースのアクセス制御
– OpenSearch ServerlessにおけるFine-Grained Access Controlの適用
– BedrockやAPI Gatewayでのリクエストログの可視化とモニタリング(CloudWatch活用)
– IAMトークンの定期更新と最小権限の原則
これによって、API経由でやりとりされるデータや、生成される出力に対する不正アクセスやインジェクションを防ぐ設計が可能になります。
モダンなアプリケーションアーキテクチャへの適用
このサーバーレスRAG構成は、チャットボット開発、社内文書検索、カスタマーサポート自動化など、幅広いビジネスシナリオに適用可能です。たとえば、企業が製品マニュアルやFAQといったドキュメントをS3上に保存し、訪問ユーザーに対してリアルタイムで最適な情報を提供するナレッジ探索ツールを構築するといった用途が考えられます。
また、Amazon BedrockやOpenSearch Serverlessを用いることで、従来よりも開発サイクルが短く、運用負担を抑えた形でRAGシステムを社内に導入することが可能になります。
まとめ:未来の業務体験を支える鍵
生成AI技術は、もはや一過性のトレンドではなく、企業の生産性や顧客体験の向上に直結する基盤技術です。そしてその中でRAGは、より「深く、正確で、信頼性の高い」出力を実現するための要となる技術です。
AWSの提供するサーバーレス型データレイクおよび関連AIサービスを活用することで、スモールスタートから大規模システムへシームレスに移行でき、なおかつ高度なセキュリティやガバナンス要件にも応える柔軟なアーキテクチャの構築が可能になります。
これからの生成AIアプリケーションは、「素早く構築し、柔軟に拡張し、安全に運用する」ことがますます求められてきます。そのため、AWSのようなクラウドインフラの強みを活かしながら、RAGのような有望技術を社内システムに積極的に取り入れる動きが、今後ますます加速していくことでしょう。
AWSを活用したサーバーレスRAGアーキテクチャの構築は、未来のビジネスを形作る第一歩となるはずです。