近年、画像や映像を扱うAI技術は著しい進歩を見せていますが、「映像に基づいた因果関係の推論」、つまり物事の因果関係を時間的・視覚的な流れから理解し、正しく推論する能力については、まだ十分に評価・研究されていません。このような課題を解決するために、研究者たちは新たなベンチマーク「VCRBench(Video-based long-form Causal Reasoning Benchmark)」を発表しました。
VCRBenchとは何か?
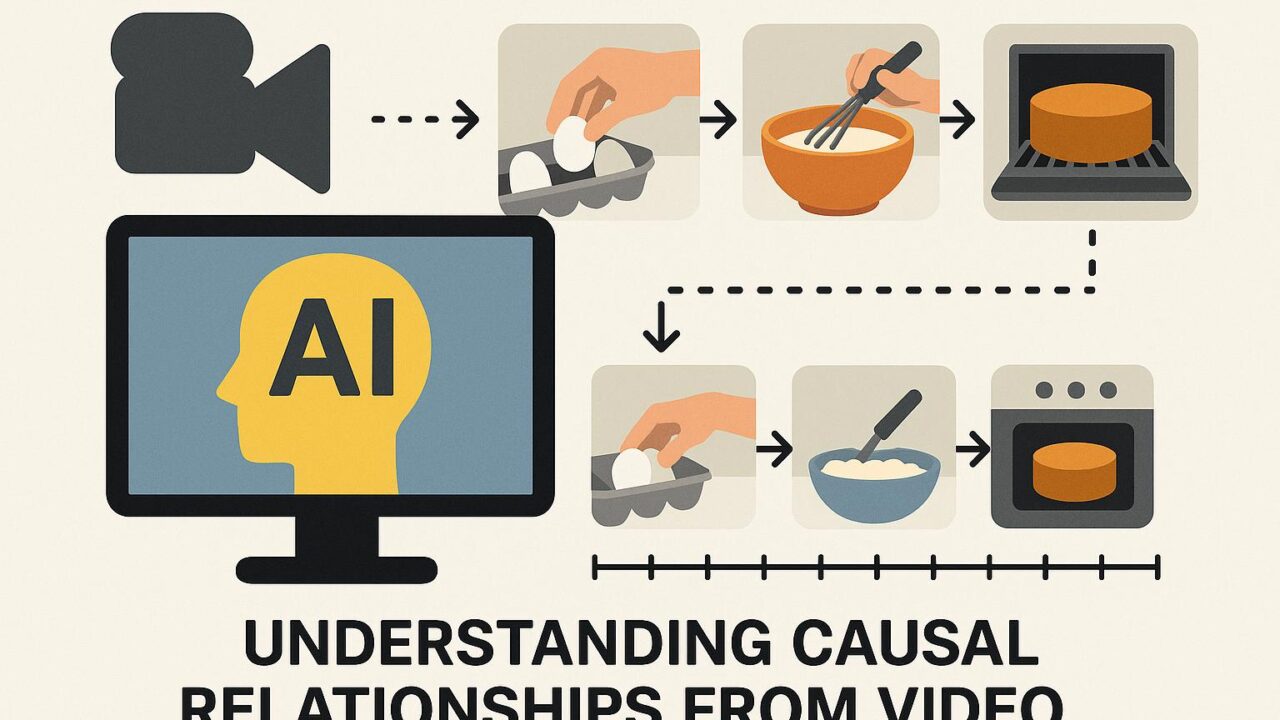
VCRBenchは、日常生活でよくある簡単な作業を題材とした「プロシージャル」動画(手順がある作業の動画)を活用し、因果関係を元に正しいイベントの順序を特定できるかを問うベンチマークです。これらの動画は意図的に手順の順番がシャッフルされていて、それぞれのクリップが「重要な因果イベント」(たとえば、ケーキを焼く前にオーブンを予熱するなど)を捉えています。
従来のベンチマークでは、あらかじめ選択肢が与えられた形(多肢選択式)や、○×のような二者択一形式で評価されることが多く、これらの形式ではAIモデルが言語的なヒント(例えば、文の構造や単語の並び)を頼りに正答を選ぶ抜け道が存在しました。VCRBenchでは、そのような「言語ショートカット」を使えないように設計されており、映像情報そのものの理解と因果関係の把握が必要になります。
現在の大規模映像言語モデル(LVLM)の限界
本研究では、ChatGPTのような言語モデルに視覚情報処理能力も持たせた最先端の「大規模映像言語モデル(LVLM)」にVCRBenchを使って評価テストを実施しました。その結果、多くのモデルは「長期間にわたる視覚情報の因果関係」を的確に把握することができず、高い誤答率を示しました。
これは、現時点のLVLMが「一つ一つの映像フレームを理解する」ことはできても、「それらが時間軸の中でどのように影響し合っているか」という因果連鎖を把握するには不十分であることを意味します。
新たなアプローチ:Recognition-Reasoning Decomposition(RRD)
この課題に対して研究チームが提案したのが「Recognition-Reasoning Decomposition(RRD)」という新しい枠組みです。RRDでは、一連の因果推論のプロセスを2つのステップに分けます。
1. 映像認識(Recognition):映像に映る出来事、物体、動作を正確に認識する。
2. 因果推論(Reasoning):認識された情報から、事象の順序関係や目的に対する因果関係を推測する。
このように処理を分けることで、各ステップの精度を向上させやすくなり、結果としてVCRBench上のモデルの正答率は最大で25.2%向上しました。
興味深い観察結果:言語知識による補完
研究の中ではさらに興味深い事実も判明しました。多くのLVLMは、複雑で視覚的な因果推論課題において、実は視覚情報よりも「内在している言語知識」に強く依存しているという点です。つまり、「過去に学んだ文脈や常識知識(たとえば、歯を磨く前に歯ブラシに歯磨き粉をつけることが多い等)」に引っ張られて推論してしまっているのです。
今後の展望と課題
VCRBenchとRRDの提案により、視覚に基づく長期的な因果関係理解の研究が一歩前進しましたが、道のりはまだ長いといえます。特に、動画というマルチモーダル(多情報形式)の媒体は、1フレームあたりの情報量が圧倒的に多く、時系列の文脈保持や注意配分、時間的整合性の維持など、多くの技術的課題を含んでいます。
今後の開発においては、視覚処理と自然言語処理の統合の精度向上に加え、「状況の変化をリアルタイムで認識し、その影響を予測する」ような人間に近い柔軟な思考スタイルの構築が求められるでしょう。
技術的まとめ
– VCRBenchは、映像ベースの因果推論能力を評価する初の大規模ベンチマーク。
– 現在のLVLMは、視覚情報のみを使った長期的因果推論に苦戦している。
– Recognition(認識)とReasoning(推論)を分離した「RRD」手法により、性能が大きく向上。
– 多くのモデルは、画像よりも事前に学習した言語的知識に依存している傾向がある。
まとめ
VCRBenchの登場により、AIが時間と因果関係をどのように理解しているかを詳しく調べることができるようになりました。人間のように「映像の流れから目的や意図を読み取る」ような高度な思考をAIに持たせるためには、今後もこのような研究がますます重要になっていくことでしょう。今後の進展が非常に楽しみな分野です。