はじめに
マルチモーダル大規模言語モデル(MLLM:Multimodal Large Language Models)の急速な発展により、視覚と言語の融合は革新的な進歩を遂げてきました。ところが、これまでの研究の多くは静的な画像・テキストの理解に焦点を当てており、実際のロボット操作や物理的な環境との相互作用には十分に適用されてきませんでした。そこで登場したのが、「RynnEC(Rynn Embodied Cognition)」です。本記事では、論文『RynnEC: Bringing MLLMs into Embodied World』を元に、MLLMとロボティクスの接続という新たな地平を紐解いていきます。
RynnECとはなにか?
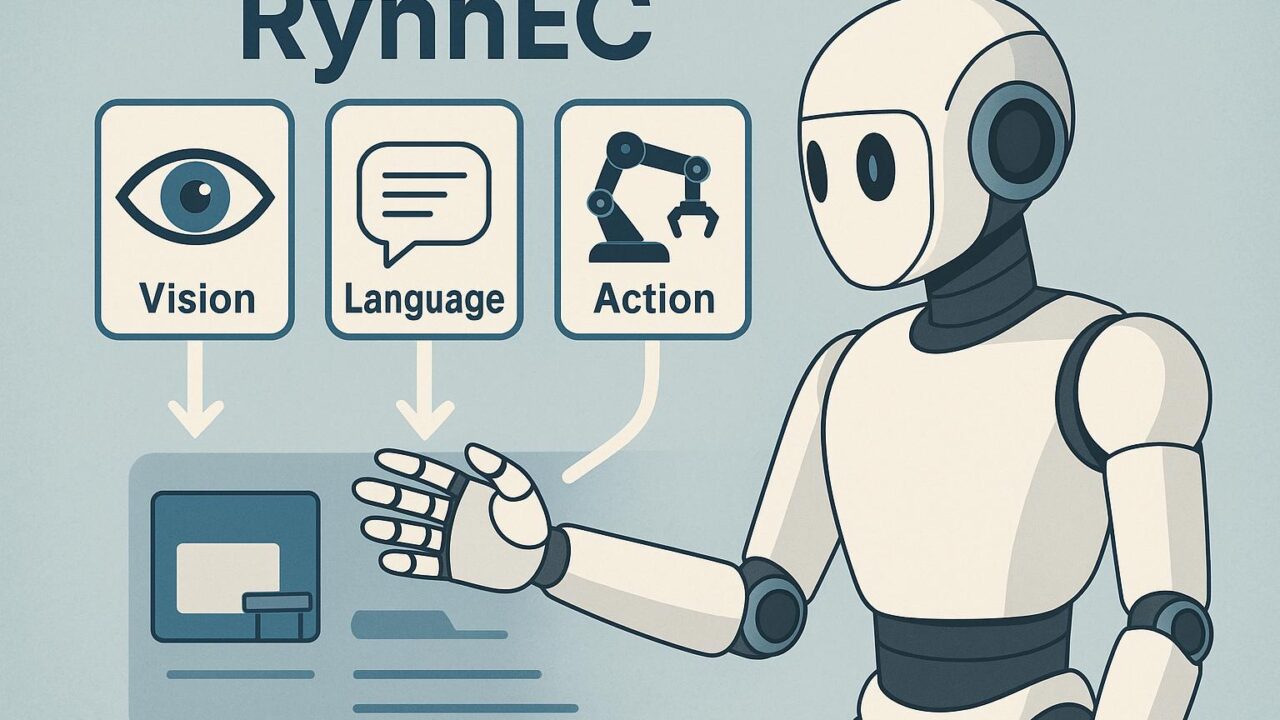
RynnECは、視覚・言語・行動の3つのモダリティを統合的に学習するための基盤モデルです。このモデルは、AIエージェントが実世界と自然かつ柔軟に相互作用するために設計されており、従来のMLLMをより実体的な環境(いわゆるEmbodied World)に移行させることを目的としています。
RynnECのアーキテクチャ
RynnECは、大まかに3つの核構造から構成されます:
- 視覚エンコーダ: 実世界内の視覚的入力を特徴マップへと変換。BYOLやMAEなど最新技術によって強化。
- 言語モデル(MLLM): 実績ある見本モデルを活用。具体的にはOpenFlamingoやMiniGPTなどを使用。
- 動作推定モジュール: 視覚・言語のコンテキストを元に適切な行動(例: オブジェクトを掴む)を選出します。
訓練方法とデータ
RynnECは大規模なマルチモーダルデータセットを活用して訓練されています。特筆すべきは、ロボティクスに特化した行動データの利用です。ここで使われるのは画像とその解説に加え、実行された動作の詳細な履歴です。これにより、モデルは「見る」「理解する」「動く」という三位一体のタスクを高精度で処理できるようになります。
応用例と成果
RynnECは、日常的なロボット支援活動から仮想環境での自己探索まで、非常に広い応用が可能です。以下はその実例です:
- 家庭用ロボットによる物品の整理整頓
- 探索型AIによる未知空間のナビゲーション
- タスク指示に対する高度な柔軟な反応(例:「カップを取ってシンクに置いて」)
実験結果では、他の強化学習モデルと比較して最大2〜3倍の精度向上と効率改善が報告されています。
RynnECの意義
この技術が目指すのは、MLLMのアクロバットな知識表現だけでなく、それを実世界で「使える知性」へとつなげることです。人間が言葉と視覚で世界を認識し、そこから行動を選択するのと同じように、RynnECも複数モダリティから意味を学び取り、自律的な判断と行動を実現します。
今後の展望
RynnECの登場により、より効率的で直感的なヒューマン・ロボット・インタラクションが期待されます。遠隔操作や介護ロボット、また災害現場での支援ツールとしての展開が現実味を帯びてきました。今後は、さらなるマルチモーダルデータの収集と、リアルタイム応答の改善が求められるでしょう。
結びに
RynnECは、いわばMLLMの「脳」に、ロボットという「身体」を与える試みです。その挑戦は、AIが見る・聞く・話すだけでなく、「行動する知性」として成熟することを示唆しています。今後の進展に注目せざるを得ません。