強化学習の基礎:やさしいQ学習(Q-Learning)入門
人工知能(AI)や機械学習(Machine Learning)が日々進化する中で、強化学習(Reinforcement Learning)はとりわけ注目されている分野のひとつです。強化学習は、エージェントが試行錯誤によって最適な行動を学ぶという学習方法であり、ゲームAI、ロボティクス、さらには自動運転などのさまざまな分野で活用されています。その強化学習の中でも、Q学習(Q-Learning)は基本的でありながらも極めて強力なアルゴリズムとして広く知られています。
本記事では、Q学習とは何か、どのように機能するのか、そしてどのようにしてQ学習が問題解決に応用されるのかについて、わかりやすく解説していきます。複雑な数学的背景に深入りすることなく、初学者の方にも理解しやすいかたちでその概念を紹介しますので、ぜひ最後までお読みください。
Q学習とは?
Q学習(Q-Learning)は、モデルフリーなオフポリシー型の強化学習アルゴリズムです。ここでいう「モデルフリー」とは、エージェントが環境の内部挙動(状態遷移や報酬構造)をあらかじめ知っておく必要がないという意味です。「オフポリシー」とは、実際に行動する方法(ポリシー)とは異なる方法で学習が進むという特徴を指します。
このアルゴリズムの基本的な目的は、「ある状態においてどの行動を選べば将来的に大きな報酬を得られるか?」という問いに答えることです。Q学習ではこの問いに答えるため、各状態-行動ペアに「Q値(Quality値)」と呼ばれる数値を割り当てます。このQ値は、ある状態で特定の行動を選択した場合に得られる期待値(将来の報酬の合計)を表しています。
エージェントは、環境と相互作用しながらQ値を徐々に更新していき、やがて最適な行動ポリシーを学習します。これによって、エージェントは未知の環境においても、最適な意思決定ができるようになります。
Q学習の仕組み
Q学習の原理は驚くほどシンプルですが、その背後には深い洞察があります。以下に、典型的なQ学習のアルゴリズムのステップを示します。
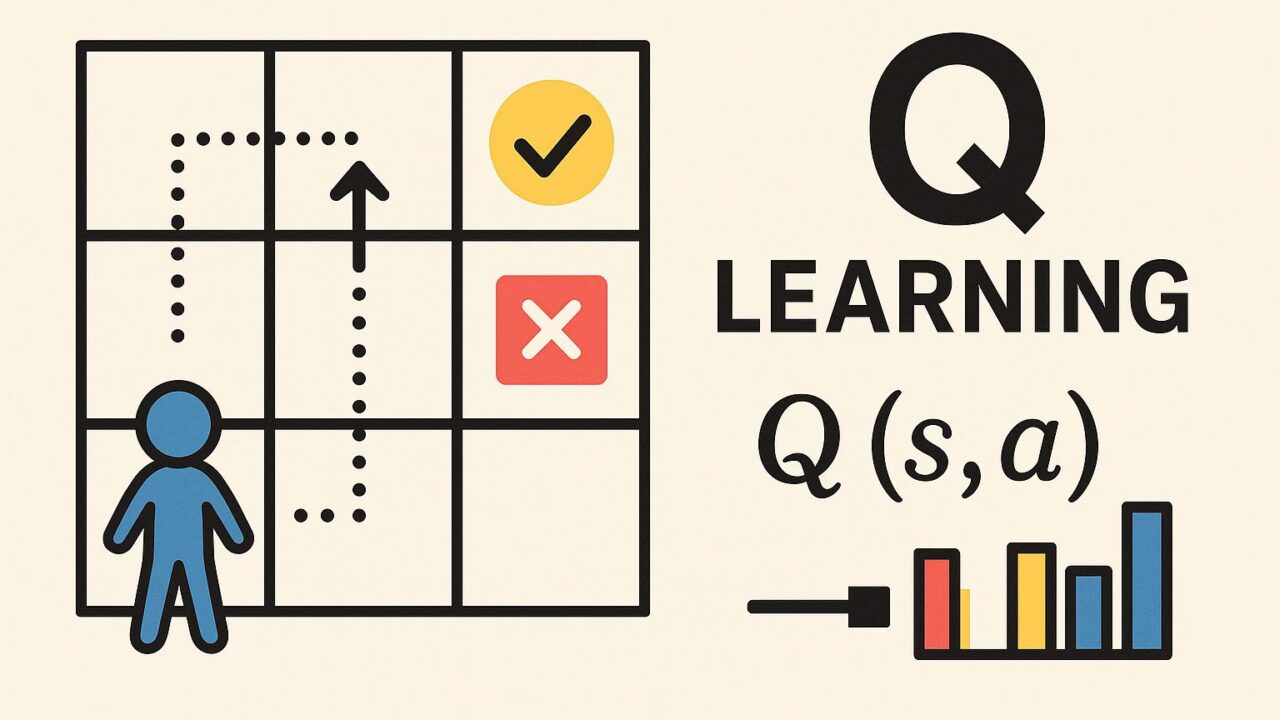
1. Qテーブルの初期化
まず、Q値を保存するためのQテーブルを用意します。これは、各状態(s)と行動(a)の組み合わせに対応する値を格納するためのテーブル(表)です。Qテーブルの各値は初期段階では任意の値(たとえば0)に設定されます。
2. 学習プロセスの開始
エージェントは環境の中で行動しながら、以下のステップを繰り返します:
(a) 現在の状態sを観測する。
(b) その状態sにおいて、探索(exploration)と活用(exploitation)のバランスを考慮して行動aを選ぶ。これは「ε-グリーディ方式」と呼ばれる方法を使うことが多く、ランダムに行動する確率εと、現在のQテーブルで最もQ値の高い行動を選ぶ確率1-εのバランスをとるものである。
(c) 選んだ行動aを実行し、次の状態s’と報酬rを得る。
(d) Qテーブルを次の式で更新する:
Q(s, a) ← Q(s, a) + α × [r + γ × max(Q(s’, a’)) – Q(s, a)]
ここで、
・αは学習率(Learning Rate)、新しい知識をどの程度取り入れるかを表す。
・γは割引率(Discount Factor)、将来の報酬にどれだけ価値を置くかを示す。
(e) 次の状態s’を新たな状態として設定し、再びステップ(b)に戻る。
これを十分な回数繰り返すことで、エージェントはQテーブルを通じて最適なポリシー(行動方針)を獲得します。
なぜ割引率が必要なのか?
割引率γの導入は、将来の報酬を現在どの程度重要と考えるかという時間的な価値観を定量化するためのものです。0<γ<1の値を取ることが一般的で、将来の報酬ほど価値が低くなるように調整されます。これは、現実世界においても将来起こる出来事よりも今すぐ得られる結果のほうが重要視される傾向があることに基づいています。たとえば、1年後にもらえる100円よりも今日もらえる100円のほうが価値があると感じるのと似ています。
学習率が意味するものとは?
学習率αは、新しく得た経験が既存の知識にどの程度影響を与えるかを決定するパラメータです。αが1に近ければ新しい情報が大きな影響を持ち、逆に0に近ければ現在のQ値をほとんど変更しないことになります。学習初期は高めの学習率を使い、多くの知識を取り入れ、徐々に学習率を下げることで安定した学習に繋がるとされています。
Q学習の真価:モデル不要な柔軟性
Q学習が持つ最大の魅力のひとつは、環境のモデルが不要であることです。現実の問題では、状態がどのように変化するか、行動によってどんな報酬が得られるのかを事前に完全に把握することは困難です。そのため、試行錯誤を通じて最適な戦略を学べるQ学習のようなアプローチは非常に有効です。
迷路のような空間を移動するロボット、戦略ゲームを攻略するエージェント、さらには交通制御や製造ラインの最適化など、多くの応用分野でモデルフリーで学習できることは大きな利点となります。
実世界への応用
では、Q学習はどのように現実の問題解決に役立てられているのでしょうか。以下はその一部の例です。
・自動運転車:他の車両や交通法規に適応しながら、安全かつ効率的に走行するために強化学習が使われています。
・倉庫ロボット:最適なルートを学習してアイテムを効率よくピックアップ・配送できるようにします。
・金融取引:市場の変動に即した取引方針を強化学習によって学び、利益を最大化するアルゴリズムを構築します。
Q学習の限界
Q学習は基礎的ながら非常に有用な手法ですが、一方でいくつかの制限も存在します。
1. 状態空間と行動空間の大きさに弱い
Qテーブルは状態と行動のすべての組み合わせを保持する必要があるため、大規模な問題(状態や行動が非常に多いケース)での適用には制限が生じます。こうした場合には、ディープQネットワーク(Deep Q-Network)などディープラーニングを組み合わせた手法がよく用いられます。
2. 離散的な問題に特化している
Q学習は基本的に状態や行動が離散的であることを前提としています。一方、連続値を取る問題への適用には工夫や拡張が求められます。
3. パラメータのチューニングが必要
学習率αや割引率γ、探索率εといったハイパーパラメータの適切な設定は、学習の成功に直結します。これらを適切に調整するには、経験や試行錯誤が必要となる場合が多いです。
学習の旅の第一歩としてのQ学習
Q学習は強化学習を理解するための出発点として最適なアルゴリズムです。そのシンプルさは多くの学習者にとって入り口として魅力的であり、実際の応用でも一定の効果を発揮します。ディープラーニングなどの複雑な要素を導入する前に、まずQ学習の原理を理解することで、より深い強化学習の世界に踏み出す準備が整います。
まとめ
Q学習は、実験と観察を通して最適な行動方針を学ぶためのシンプルかつ効果的なアルゴリズムです。その基本構造を学ぶことで、強化学習の全体像にもより深い理解を得ることができるでしょう。ゲーム、ロボティクス、金融、物流など、現代のさまざまな課題に対して応用可能な強力なツールとして、今後もその重要性は高まり続けるでしょう。
Q学習の深淵に一歩踏み出すことは、機械学習の理解を深め、さまざまな分野での問題解決能力を高める貴重な第一歩となるはずです。興味がある方は、ぜひ実装やシミュレーションを通じてその力を体感してみてください。学ぶほどに、その奥深さと可能性を実感できるに違いありません。