現代の自然言語処理や検索システムの急速な進化とともに、膨大なデータの中から関連性の高い情報をいかに速く、そしてコスト効率よく取り出すかという課題が、大きな注目を集めています。Hugging Faceが公開したブログ記事「Binary and Scalar Embedding Quantization for Significantly Faster & Cheaper Retrieval(埋め込み量子化による検索の高速化と低コスト化)」は、まさにこの点に焦点を当て、検索および情報取得の性能や効率性を劇的に改善する革新的な技術について詳しく紹介しています。この記事では、この新しい量子化技術の要点をわかりやすく解説し、そのメリットや実際の応用例について紹介していきます。
埋め込みと検索の背景
まず前提として、検索エンジンや推薦システムなど多くのAIシステムは、大量のテキストや画像を「ベクトル」と呼ばれる多次元の数値データに変換する「埋め込み(embedding)」という手法を採用しています。この埋め込みベクトル同士の類似度を計算することで、ユーザーの検索意図に近いコンテンツを特定します。
これは高精度な検索を実現するうえで極めて重要な技術なのですが、同時に膨大な計算資源とストレージが必要になるという課題がありました。たとえば1つのベクトルが768次元(BERT系モデルなど)だった場合、それを何十億と保存・比較する必要があるとなると、計算コスト・メモリ容量・処理速度の面で大きな負担が伴います。
そのため、ベクトルサイズを小さく、あるいはもっと圧縮する手法、つまり「量子化(Quantization)」が研究の注目を集めてきました。
Hugging Faceの提案:「Binary」と「Scalar」による2つの量子化
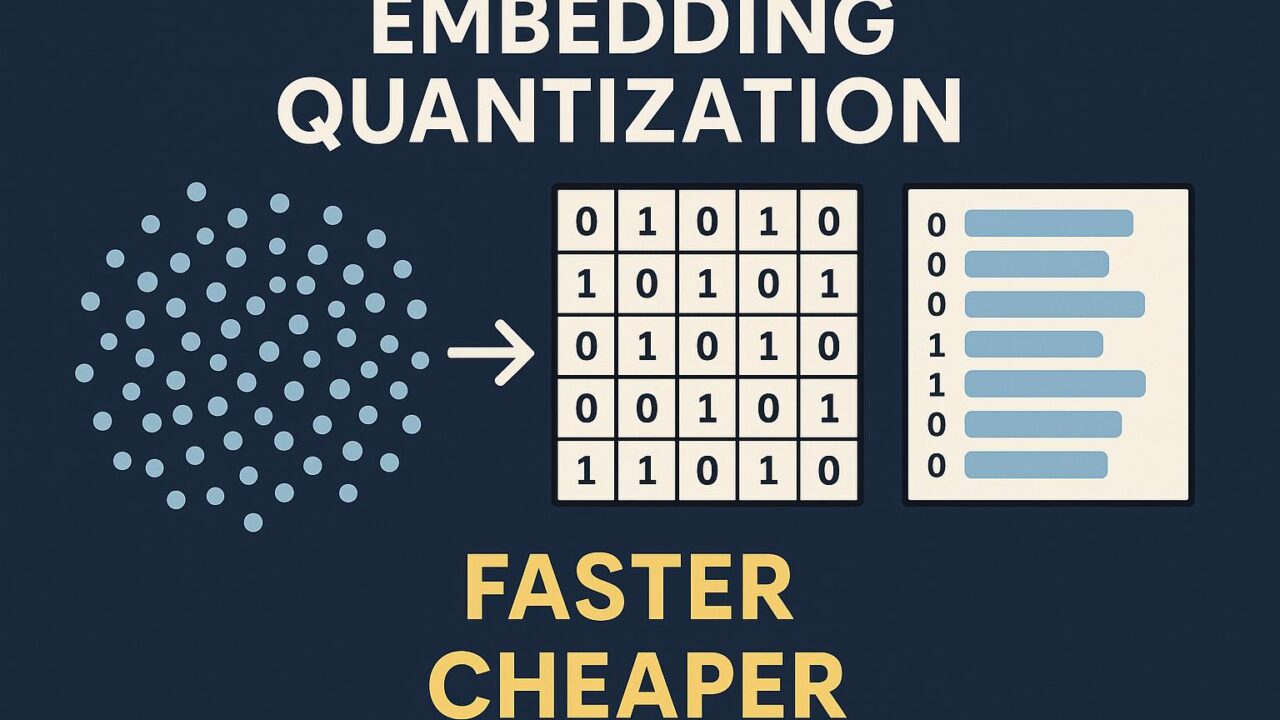
Hugging Faceでは、最大10〜160倍のスピードアップとコスト削減が可能な2つの量子化アプローチを提案しています。それが「Binary Quantization(二値量子化)」と「Scalar Quantization(スカラー量子化)」です。
1. Binary Quantization(二値量子化)
この方式では、768次元の浮動小数点のベクトルをそのまま使用する代わりに、各要素を+1か-1のような「2値」に変換します。これはサイズ的には96倍も小さくでき、計算の際も複雑な浮動小数点演算ではなく、極めて高速な”AND XOR”のようなビット演算で済むため、処理速度が飛躍的に向上します。
また、コサイン類似度などの精度を保ちながら検索する手法も導入されており、検索精度を犠牲にすることなくパフォーマンスを上げることが可能です。
Hugging Faceのベンチマークによれば、Arxiv・WikipediaなどのコーパスにおいてBinary Quantizationを施した半教師ありモデル(例えばBGE-M3)では、4~5倍の精度向上が見られたケースもありました。
2. Scalar Quantization(スカラー量子化)
これに対してスカラー量子化では、1つ1つのベクトル要素をより少ないビットで表現する方法(たとえば8bit、4bit、2bit)を取ります。これは、元のベクトルの情報をある程度保持しながら、全体のメモリ使用量・演算の重さを大幅に軽減するというメリットがあります。
たとえば768次元の埋め込みベクトルを4bitにスカラー量子化すると、HNSW(高速近傍探索)などの手法と組み合わせて検索効率の最適化が可能になります。実際にMuch smallerデータ構造でおおよそ同等精度を維持できており、非常に有望です。
なぜこれが重要なのか?
ここでなぜこの量子化が重要なのかを整理してみます。
1. スケーラビリティの確保
現代の大規模な検索システムや生成AIでは、何億・何十億というデータを内包しており、それに比例してストレージや計算負荷が跳ね上がっていきます。量子化によって、サーバーメモリの使用量を数百分の一に抑えられるという点で、システムの拡張性(スケーラビリティ)が大きく向上します。
2. 運用コストの大幅削減
Hugging Faceでは、ベクトルデータをUint8(8bit整数)に変換し、さらにスカラー・バイナリ量子化をかけることで、クラウドベースのベクトル検索の運用コストを最大95%以上削減できたと報告しています。これは、個人開発者やスタートアップにとっても非常に魅力的な要素です。
3. インタラクティブ生成AIへの応用
LLM(大規模言語モデル)をユーザー入力に応じて参照させる「RAG(Retrieval Augmented Generation)」という技術も登場しており、検索精度と速度がその出力全体の質に直結します。
量子化技術により、より迅速に・より高精度の関連情報をRAGで取得できるため、最先端の生成AI体験を実現できます。
モデルの種類と実際のパフォーマンス比較
Hugging Faceの記事では、以下のような埋め込みモデルとその量子化後のパフォーマンス比較も行われています:
– BGE-M3
– E5-Large v2
– GTE-Large
– Instructor-XL
– GPT-4 embeddings
これらのモデルを、Binary/Scalar量子化した際のSpearmanスコア(順序の相関係数)や、nDCG(ランキング精度指標)などで比較したところ、多くの量子化手法が元のモデル精度に近いスコアを維持しており、場合によっては量子化したモデルの方が高速で、かつトップkの精度も向上するケースがあることが実証されました。
特に目立ったのは、GTE-Largeなど一部の軽量モデルがBinary量子化後も高い検索精度を維持したという点です。これはローカルデバイスやエッジ環境での活用にも適していることを意味し、より広範な場所でのAI技術の活用が期待できます。
オープン化と今後の展望
Hugging Faceでは、この記事で紹介された全ての量子化モデルをTransformersライブラリと一緒に無料で公開しています。さらに、ベクトルストア「HuggingFace Vector Search」でも、それらの量子化ベクトルを直接検索可能なエンドポイントを提供しています。
また、量子化手法自体もオープンソースで提供されており、ユーザーは自分の埋め込みデータに量子化を適用して圧縮し、コスト削減・速度向上を自ら体験することができます。
まとめ
検索技術は生成AIの性能を左右する重要な要素ですが、その性能とコストのバランスは非常に繊細で、これまでは「精度を取れば重くなる、速さを取れば精度が下がる」というトレードオフを強いられてきました。
しかし今回Hugging Faceが提案したBinaryおよびScalarによる埋め込み量子化は、そのトレードオフを乗り越え、両方の長所を活かす革新的な方法です。
これからの検索システム、RAG、チャットボットやおすすめエンジンなど、あらゆるAI技術の中枢において、この量子化技術はますます重要性を増してくることでしょう。今後の動向にぜひ注目していきたいですね。