- Amazon: Deep Learning(Goodfellow 他)
- Amazon: Pattern Recognition and Machine Learning(Bishop)
- 楽天: Deep Learning(Goodfellow)を楽天で探す
- 楽天: PRML(Bishop)を楽天で探す
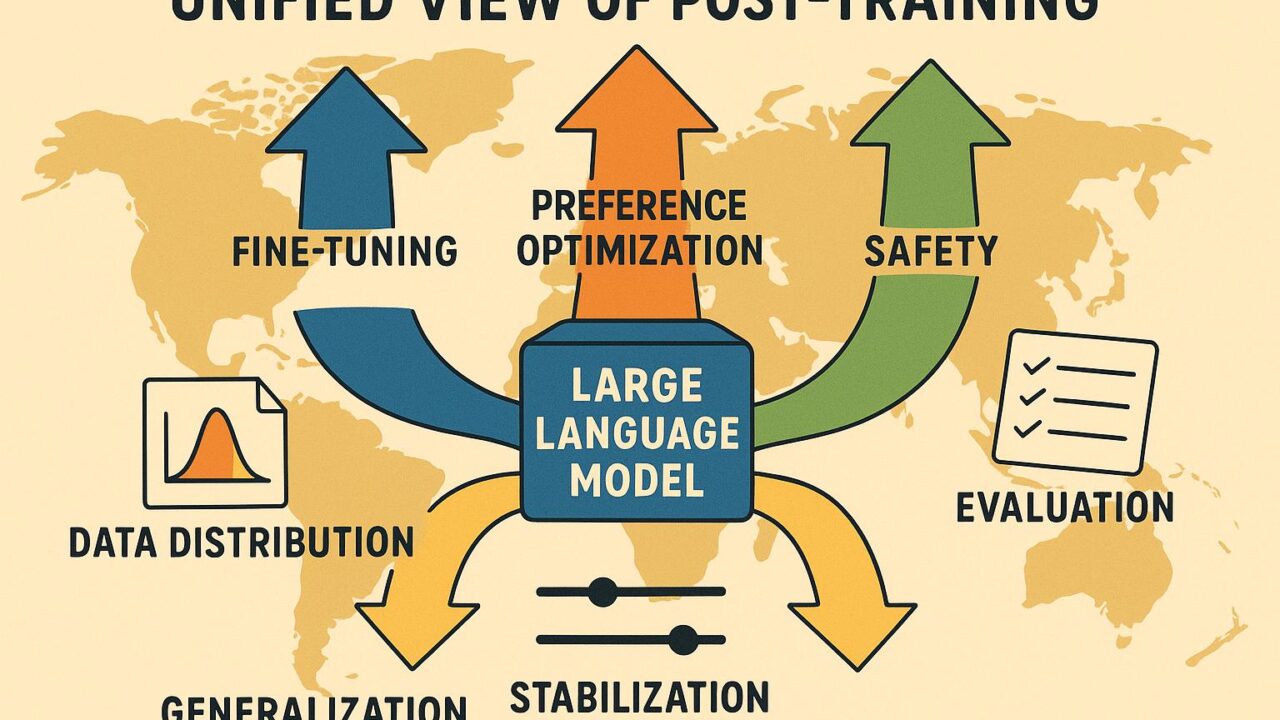
要旨:ポストトレーニングの“統一地図”が示すもの
「Towards a Unified View of Large Language Model Post-Training」は、その題が示す通り、SFT(監督微調整)、RLHF(人間のフィードバックによる強化学習)、DPO/KTO/IPO などの好み最適化の手法、RLAIF(AIフィードバック)や安全微調整までを、ひとつの原理で見通そうとする試みです。私の読み取りでは、核となるメッセージは次の三点です。
- 多様なポストトレーニング手法は、KL 正則化付きの方策最適化や変分推論(Control as Inference)といった共通の数理に還元できる。
- 「報酬モデル vs 直接法(DPO など)」の二項対立より、データ分布設計(プロンプト・応答の混合、フィードバックの質、カバレッジ)と安定化正則化が成否を決める。
- 評価もまた統一的に捉えられ、オフポリシー評価・校正・リスク感度を含めた多面的計量が必要。
主流解釈との“ズレ”はどこにあるか(3点)
一般に予想される主流解釈と、本論文が示唆する統一的視点との違いを三つ挙げます。
- 手法の差異強調 → 原理の共通性強調
主流は「RLHF と DPO は別物」とみなしがち。一方、本論文の狙いは、両者が KL 正則化を介して同じ目的関数の近似や別解釈に過ぎない点を照らす方向にある。 - 報酬モデル中心 → 分布設計・正則化中心
主流は「良い報酬モデルを作る」へ傾きがち。本論文は、データ分布(SFT の土台や好みデータの多様性)と KL バジェットや温度・重み付けといった安定化が決定的だと位置付ける。 - 単一指標での勝敗 → 多面的評価・安全性の統合
主流は単一のベンチでの高得点を競う傾向。本論文は、オフポリシー評価、校正、ジャイルブレーク耐性、偏りの測定など“複数次元の健全性”を同一フレームで扱う重要性を強調する。
この“ズレ”が意味すること:短期と中期の見通し
- 短期(数週間〜数ヶ月)
現場のパイプラインは収斂し、SFT → 好み最適化(DPO/IPO 等) → 安全微調整 → 多面的評価という“標準レシピ”が整理される。アルゴリズム選択よりも、データ混合と KL/温度のチューニング、オフポリシー評価の導入が差を生む。計算資源とコストの即効的な削減が起こる。 - 中期(1〜3年)
手法のコモディティ化が進み、価値の源泉が「データ品質・評価設計・安全運用」に移る。中小チームでも小〜中規模モデルを高品質に仕上げやすくなり、国・言語圏ごとの文化的好みや規制を反映したポストトレーニングが普及。教育・公共領域でも“統一フレーム”に基づく調達・評価が広がる。
統一フレームの中身:実装者視点の整理
- 共通目的関数:最大化したいのは「望ましい応答の確率(好み)」と「元モデルとの距離(KL)やエントロピーのバランス」。RLHF も DPO も、このバランスの取り方・近似方法が異なるだけ、という捉え方。
- データ設計:SFT の下地づくり(指示追従のカバレッジ)、好みデータの多様性(難易度・タスクミックス)、合成フィードバック(RLAIF/自己プレイ)をバランス良く。
- 安定化の鍵:KL バジェット、温度、重み付け、オフポリシー比のクリッピングなど。過学習・報酬ハッキング・モード崩壊の防止を“方策改善の一部”として扱う。
- 評価:リーダーボード一点張りではなく、校正(自信と正答の整合)、逸脱検知(安全・越権回答の抑制)、再現可能性、長文整合性、ドメイン適合といった多角評価を組み合わせる。
日本とグローバル経済・社会課題との関係
統一フレームは、日本語圏の好み・規範を丁寧に埋め込む実務に向いています。公共分野では説明責任・安全性を評価指標に織り込みやすく、産業ではコスト効率と責任ある利用の両立がしやすい。グローバルでも、規制準拠や文化差を尊重したローカル適応の技術基盤として効くでしょう。
ここが独自解釈だ
- 好み最適化を“単一目的”ではなく、マルチオブジェクティブ最適化(有用性・安全性・多様性・公平性)として捉え、ガンマや温度を“重みスライダー”と見立てると、運用が理解しやすい。
- 炭素・電力コストの観点で、統一フレームは再学習回数とチューニング探索を減らせる。省エネは中期の競争力に直結する。
- 評価の“測定誤差”(ヒューマン審査のばらつき、オフポリシーバイアス)をモデル不調と取り違えない体制づくりが、現場では最重要の一つ。
見逃されがちなポイントの補足
- プロンプト分布の設計:評価時のプロンプト分布が実運用と乖離すると、統一フレームでも“正しくない最適化”になる。実データを定期的にサンプリングして評価分布を更新する。
- 蒸留と整合:強いポリシーを軽量モデルへ蒸留する際も、KL とカバレッジの管理が要。蒸留の“教師”が取りこぼした多様性を補うには、データ拡張や温度調整が効く。
- 安全・越権ガード:拒否のしすぎ(過度に保守的)と緩さのバランス。閾値・ルーブリックを方策改善ループに組み込むと、運用後のドリフトへの追随が楽になる。
実務へのチェックリスト
- 目的関数を「有用性×安全×多様性×原モデルからの乖離」の折衷と明文化する。
- データ混合(SFT/好み/安全/合成)の比率を管理し、逐次 A/B で検証。
- KL/温度/重み付けのチューニングは体系化して、再現可能なベースラインを持つ。
- 評価は、性能・安全・校正・長文整合・公平性の最低5軸でスコアカードを作る。
- 蒸留や更新のたびにオフポリシー評価でドリフト検知を行う。
学びを深めるための参考図書
- Deep Learning(Goodfellow 他):表現学習の基礎を固め、SFT の土台理解に。
- Pattern Recognition and Machine Learning(Bishop):確率的モデリングと正則化の直観を養う。
- 楽天での検索結果も活用ください。
まとめ
ポストトレーニングの統一的視点は、「手法間の違い」を超えて「目的関数と分布設計」に光を当てます。短期的にはパイプラインの標準化とコスト削減、中期的にはデータ品質・評価・安全運用が競争優位の核になるはずです。日本語圏の価値観や規制に合う“望ましさ”を、理論的に筋の通った手順でモデルへ落とし込む。その実践を支えるのが、この“一枚の地図”です。
- Amazon: Deep Learning(Goodfellow 他)
- Amazon: Pattern Recognition and Machine Learning(Bishop)
- 楽天: Deep Learning(Goodfellow)を楽天で探す
- 楽天: PRML(Bishop)を楽天で探す