- Amazon: 強化学習 第2版(Sutton & Barto)
- Amazon: Pythonで学ぶ強化学習 入門
- Amazon: Pythonではじめる数理最適化
- Rakuten: 強化学習 第2版(Sutton & Barto)
- Rakuten: Pythonで学ぶ強化学習 入門
- Rakuten: Pythonではじめる数理最適化
SATQuestとは何か——論理の土俵でLLMを裁く「検証器」
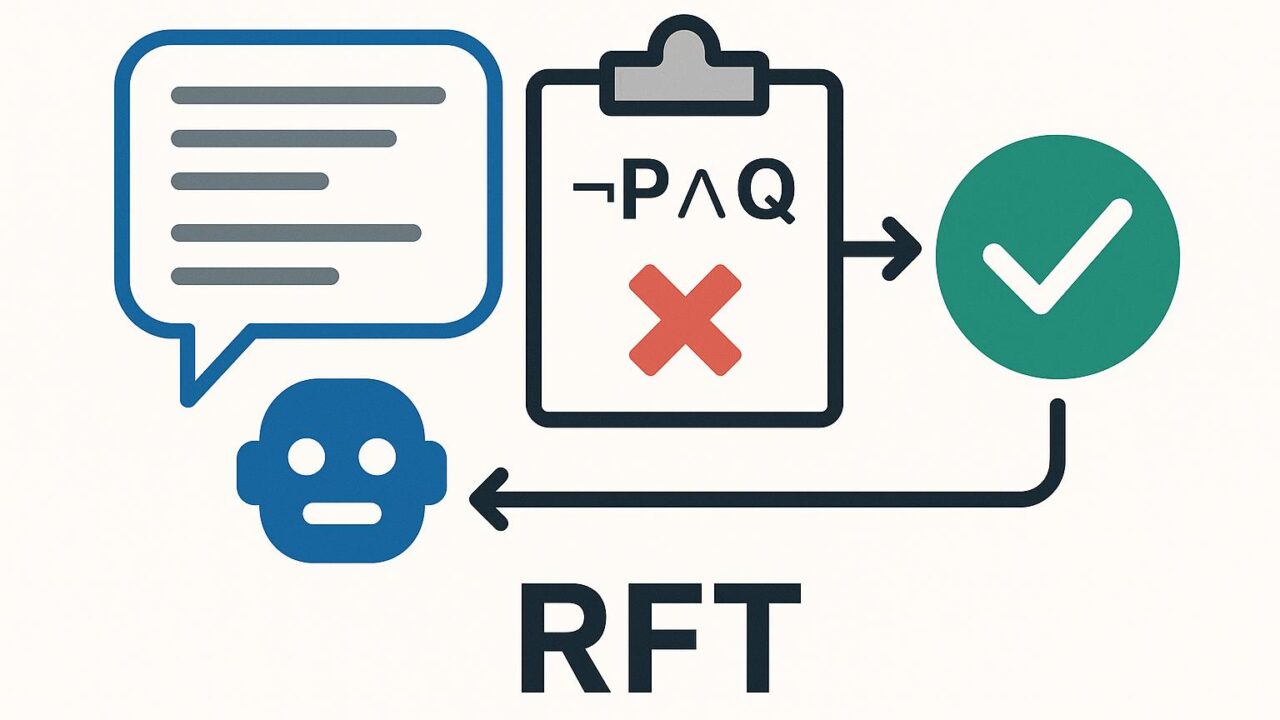
タイトルが示すとおり、SATQuestはLLMの論理推論能力を評価するための「検証器(Verifier)」であり、その検証信号を使って強化学習ベースで微調整(Reinforcement Fine-Tuning, RFT)まで一気通貫に回す設計思想が核です。SAT(充足可能性)問題に代表される形式論理のフレームで、モデルの回答が論理的に整合しているかを判定し、合格・不合格あるいは部分点のかたちで報酬化します。これにより、従来の最終答え一致やヒューリスティックな自動採点を超えて、推論過程と構造的正しさに照準を合わせた評価・学習が可能になります。
主流解釈とのズレ:3つの論点
一般には、LLM評価は「最終回答の正誤」「チェーン・オブ・ソートの長さ・一貫性」「ベンチマーク(GSM8KやMATH)での精度」あたりに集約されがちです。SATQuestが投げかける視点は次の3点で主流と異なります。
- 形式検証ファースト:感覚的・統計的な正答率より、論理制約を満たすかどうかを第一原理で判定。自然言語のあいまいさを、SAT/MaxSAT/SMTなどの形式系にマッピングします。
- 報酬の設計が厳密:ルーブリックではなく論理制約で報酬を定義するため、RFTの信号が明確。探索を伴うタスクでも、検証器の合否が学習を安定させます。
- 汎化の方向性:言語コーパス依存ではなく「制約充足能力」へ一般化を誘導。見かけの文脈整合より、解の存在・一意性・整合性に強いモデルを目指します。
ズレが意味すること:短期と中期のインパクト
- 短期(数週間〜数ヶ月):
・ベンチマークでのスコア評価に加え、論理制約に基づく追加評価が導入され、モデル選定の基準が二軸化。
・既存モデルに対してもVerifier付き推論(検証→リトライ)だけで性能が底上げ。
・プロダクションでは、仕様やルールを制約として書き下ろし、出力検証→自動修正のガードレールが標準化。 - 中期(1〜3年):
・RFTやDPOに「検証器由来の報酬」を組み込む実務フローが普遍化し、LLM開発は「モデル×検証器」の共同最適化へ。
・コンプライアンス・金融・医療・公共調達など監査性を重視する領域で、形式検証に準拠したAI品質基準が整備。
・教育・スキル評価でも、記述式解答を論理制約で判定する評価ツールが普及。
日本・グローバル経済・社会課題との関係
日本の現場で重視される「品質・安全・トレーサビリティ」は、まさにSATQuest的な検証器アプローチと相性が良好です。製造業の設計チェック、金融商品の適合性判定、行政のルール準拠確認などで、自然言語の仕様を形式制約へ落とし込むだけで自動検証・自動修復のパイプラインが構築できます。グローバルでも、ハルシネーション抑制や説明可能性、監査対応の要請は高まっており、Verifier-firstなAIは社会受容性の鍵になっていきます。
どのように使うか:実装の現実解
- 制約の定式化:タスク(スケジューリング、ロジックパズル、仕様充足、単純なコード合成など)をCNF/SMTへ落とし、検証器で判定。MaxSATを使えば部分点も可能。
- 推論ガードレール:推論時に(1)ドラフト出力→(2)検証→(3)失敗時の自動修正プロンプト→(4)再検証、を数回ループ。これだけでも実務で効きます。
- RFT/DPO連携:検証結果を報酬としてバッチ収集し、方策更新。コストは増えるため、キャッシュ・漸進SAT・カリキュラム学習・難易度調整で削減。
- データ拡張:生成タスクに制約を付与した自動問題作成→検証器で厳選→学習、のループでクリーンなデータセットを確保。
ここが独自解釈だ(筆者の視点)
- 検証器は「評価者」ではなく「共演者」:モデルと検証器を同じ一つの製品として設計・保守することで、機能追加の速度と品質が大幅に上がる。
- 言語モデルの「論理力」はスケールではなく「制約表現力×探索戦略」で決まる:パラメータを増やすより、制約をどう書けるか・フィードバックをどう返すかが効く。
- ビジネス価値は「正答率」より「契約・規制遵守率」:監査証跡と再現可能性を備えた推論こそ、現場での意思決定を支える。
見逃されがちな論点
- コストと遅延:SAT/SMTは最悪時に重い。対策は、問題分割、漸進的検証、キャッシュ、部分検証(制約サブセット)でレイテンシを管理。
- 制約の品質:曖昧な仕様を無理に形式化すると逆効果。最初は狭い領域で厳密ルールを運用し、徐々に適用範囲を拡張するのが堅実。
- 人間の介在:自動化の要は「制約レビュープロセス」。コードレビュー同様に、制約の可読性・モジュール性・テストを文化として定着させる。
実装ステップのひな型
- ユースケースの洗い出し(例:FAQ自動回答の規約準拠、スケジュール自動生成の制約充足)。
- 制約の形式化(CNF/SMT、あるいはドメイン特化DSL)。
- 推論パイプラインに検証器を挿入(失敗時に自己修正プロンプトを返す)。
- 検証ログから報酬データを作り、RFT/DPOで微調整。
- 品質ゲート(監査用の失敗例・修正履歴・検証結果の保存)。
まとめ
SATQuestは、LLMの「言語らしさ」ではなく「論理の頑健さ」で評価・学習させる転換点を示しています。短期的には推論ガードレールとして導入するだけでも品質は上がり、中期的には検証器とモデルを一体で開発する体制が競争力を左右するでしょう。形式検証は難しそうに見えても、最小限の制約から始め、徐々に拡張することで実務効果を早期に得られます。論理で守り、論理で攻める。そんなVerifier-firstのAI開発を、今日から試してみませんか。
- Amazon: 強化学習 第2版(Sutton & Barto)
- Amazon: Pythonで学ぶ強化学習 入門
- Amazon: Pythonではじめる数理最適化
- Rakuten: 強化学習 第2版(Sutton & Barto)
- Rakuten: Pythonで学ぶ強化学習 入門
- Rakuten: Pythonではじめる数理最適化