- Amazon: ゼロから作るDeep Learning 3 フレームワーク編 | ゼロから作るDeep Learning 2 自然言語処理編
- 楽天: ゼロから作るDeep Learning 3 フレームワーク編 | ゼロから作るDeep Learning 2 自然言語処理編
長時間動画を本当に「理解」するには
長い動画を見終えるまでに、私たちは心の中で「いつ」が重要で、「何」が起きたのかを自然に整理しています。これを機械に求めると、大きな壁にあたります。動画はフレームが膨大で、出来事は散らばり、登場する人物やモノ(エンティティ)は時間とともに動き、見え方も変わるからです。タイトルが示す「When and What: Diffusion-Grounded VideoLLM with Entity Aware Segmentation」は、まさにこの二つの要素—時間的な『いつ』と対象の『何』—を両輪として扱い、長時間動画をより確からしく理解する発想を掲げています。
Why: 長い動画で起きがちな3つの問題
- 情報の希釈:重要な瞬間が埋もれやすい。
- 言語–画素ギャップ:言葉での問いに対し、どの画素・どの時間を根拠にすべきかが曖昧。
- エンティティの一貫性:同じ人物・物体を時間を越えて同一視するのが難しい。
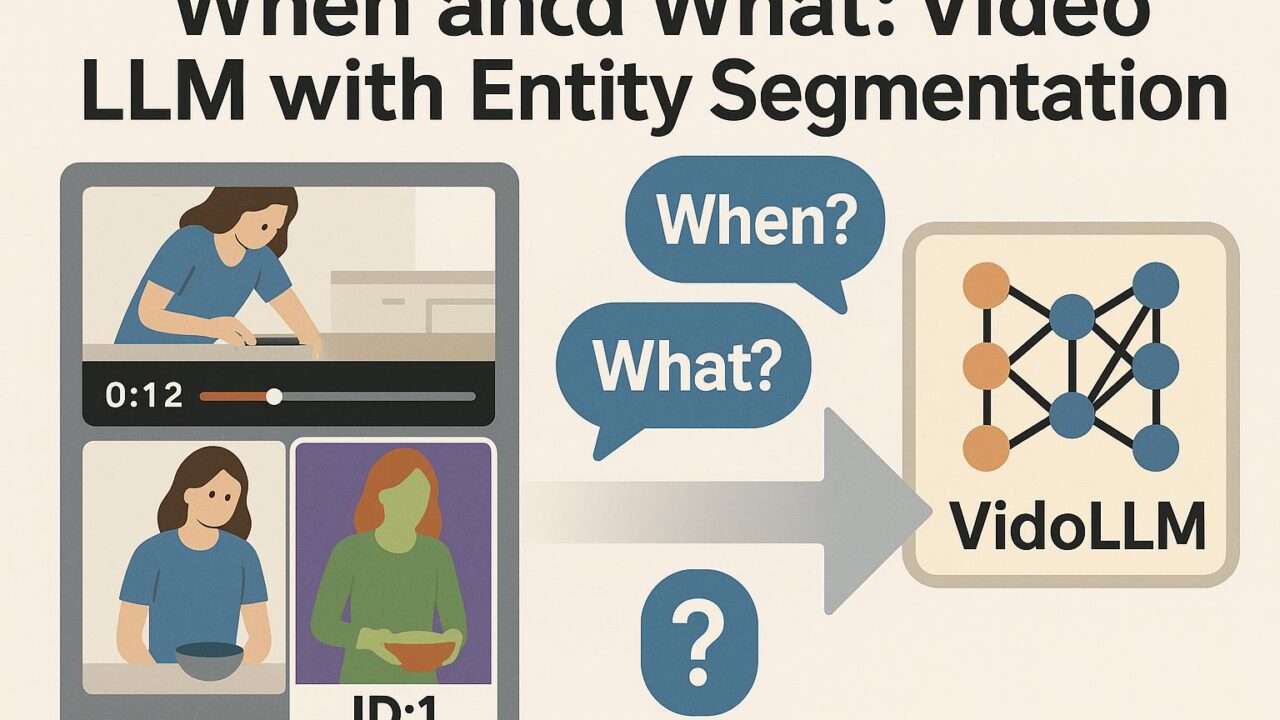
この研究が目指す方向性は、動画のどこを読むべきか(When)を見極め、何を指しているのか(What)を画素レベルで根拠付けし、言語モデル(VideoLLM)に渡すことです。
What: 拡散モデルで「根拠」を作る、エンティティで「意味」を保つ
キーワードは「Diffusion-Grounded」と「Entity Aware Segmentation」。前者は拡散モデル(Diffusion)を根拠付けに活用し、後者は人物や物体といったエンティティをセグメンテーションで一貫して追跡・識別する方針です。
- When(いつ)を絞る:拡散モデルの生成過程やスコアを活用し、時間的に顕著な区間やショット境界、出来事の候補を抽出。LLMに全フレームを丸投げせず、要点区間を優先的に読む流れを作ります。
- What(何)を指すか:エンティティ指向のセグメンテーション(Entity Aware Segmentation)により、同じ人物や物体をID付きで追跡し、マスクとして切り出します。これにより、説明時に「誰(何)が、どこで、何をした」を画素レベルの根拠で示せます。
- LLMへの橋渡し:抽出した区間とエンティティ情報を、圧縮した視覚トークンとともにVideoLLMへ。プロンプトには時間レンジやエンティティ名(または役割)を組み込み、質問に対して該当部分を参照しやすくします。
How: パイプラインのイメージ
- 軽量サンプリング:長時間動画を低FPSで粗取りし、ストリームを整理。
- 拡散グラウンディング:拡散モデルで顕著区間を抽出し、候補セグメントを作成。
- エンティティ分解:各セグメントで人物・物体をマスク化し、IDを保ったまま追跡。
- 階層メモリ化:セグメントごとに要約し、時間順・エンティティ順の二軸で整理。
- 質問指向の読解:ユーザの問いに応じて、関連セグメント+エンティティの根拠を束ね、VideoLLMで回答・要約・字幕生成などを実行(根拠のタイムスタンプとマスクを提示)。
学習と評価の一般的な考え方
こうしたシステムでは、QA・要約・キャプション・時間定位など複数タスクの指示データを活用し、映像と言語の整合を鍛えます。拡散グラウンディングとエンティティ追跡は、擬似ラベルや弱教師ありでブートストラップする戦略も考えられます。評価は、時間的一致(いつが正しいか)、エンティティ追跡の一貫性(例:ID一致の指標)、回答の正確さ・根拠の妥当性(ユーザが根拠を視認できるか)といった複数軸で行うのが自然です。
なぜ拡散モデルなのか
拡散モデルは生成過程で多様な仮説を探索し、スコアで不確実性を扱えるため、動画の「どこが重要か」を見積もる際に有用です。注意ヒートマップだけに頼るより、局所的で画素的な根拠が得られ、後段のLLMが参照すべき領域・時間を明示しやすくなります。結果として、回答に「この時間帯・この対象が根拠です」と説明可能性が付与され、ユーザ側の納得感が高まります。
使いどころ:人がうれしい“根拠つき”の理解
- 教育・研修:長い講義動画を「どの時間・どの概念」に紐付けて要約し、巻き戻しなしで復習。
- スポーツ解析:得点や失点の直前後にフォーカスし、関与エンティティ(選手・ボール)の動きを可視化。
- 会議・顧客サポート:論点の発生区間を自動特定し、発言者/資料領域を根拠として提示。
- 製造・監視:異常の予兆区間と関与機器をハイライトし、原因究明の時間を短縮。
実装のヒントと運用の注意
- 計算資源とストレージ:長時間動画は重いので、先に時間的サンプリングと圧縮で軽量化。
- セグメント先行:全フレーム入力ではなく、まず「When」を絞る戦略がコストと精度の両面で有効。
- 評価設計:時間定位(いつ)、エンティティ一貫性(誰・何)、回答妥当性(なにを言ったか)を分けて測る。
- ヒューマン・イン・ザ・ループ:根拠(タイムレンジとマスク)を人が確認できるUIを併設すると、現場導入が進みやすい。
- 倫理・プライバシー:顔や個人情報が映る場合はマスク処理やアクセス制御を徹底。
まとめ:「いつ」と「何」を分けて、最後に束ねる
長時間動画理解の難しさは、情報の多さだけではなく、正しい「場所と時間」にたどり着けるかにあります。拡散モデルで時間的・画素的な根拠(Whenの絞り込み)を得て、エンティティセグメンテーションで対象の意味(Whatの同一性)を保つ。そのうえでVideoLLMに渡すと、回答が人に説明しやすく、再現性のある振る舞いになります。現場が求めるのは、ただ当たるAIではなく、なぜそう言えるのかが示せるAIです。本稿のキーワードは、その実現に向けた実践的な合言葉になるはずです。
学習と実装の助けになる書籍
- ゼロから作るDeep Learning 3 フレームワーク編:モデルの構成要素を自作しながら、長時間動画向けの前処理・メモリ設計にも応用が利く実装力を養えます。
- ゼロから作るDeep Learning 2 自然言語処理編:VideoLLMの言語側を強化し、質問応答や要約の品質を土台から高めるのに役立ちます。
- Amazon: ゼロから作るDeep Learning 3 フレームワーク編 | ゼロから作るDeep Learning 2 自然言語処理編
- 楽天: ゼロから作るDeep Learning 3 フレームワーク編 | ゼロから作るDeep Learning 2 自然言語処理編