近年、自然言語生成の分野ではトランスフォーマー(Transformer)と呼ばれるモデルが圧倒的な注目を集めています。特に、Llama-2やLlama-3のようなデコーダ専用(decoder-only)トランスフォーマーは、特定のタスクにおける高性能な言語生成モデルとして高く評価されています。これらのモデルは、チャットボットやコード生成、創作支援といったさまざまな応用で活用されており、今や日常に溶け込んだ存在になっています。
本記事では、『Building a Decoder-Only Transformer Model Like Llama-2 and Llama-3』という記事をもとに、Llama-2やLlama-3のようなデコーダのみのトランスフォーマーモデルをどのように構築するかについて、わかりやすく解説していきます。モデルのアーキテクチャ設計、実装時のポイントから学習プロセスに至るまでを丁寧に紹介し、これから自分でトランスフォーマーモデルを構築したいと考える方にも役立つ内容になっています。
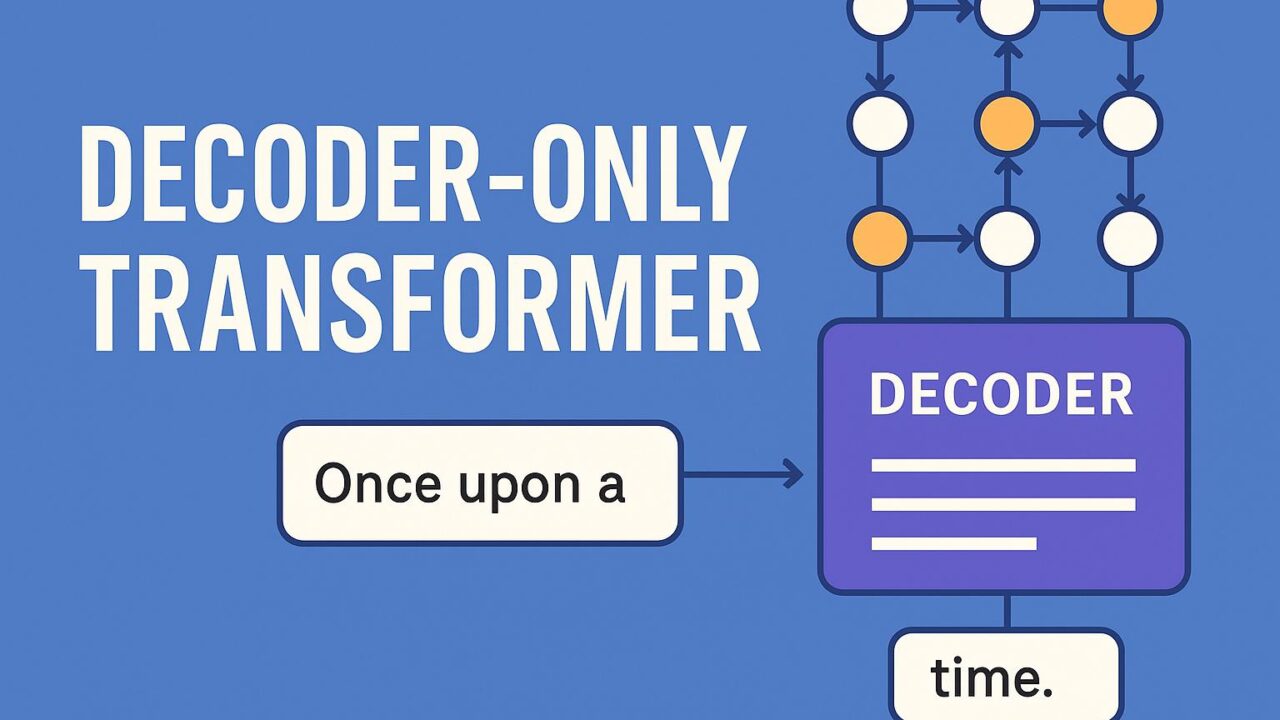
デコーダ専用トランスフォーマーとは?
まずはじめに、デコーダ専用のトランスフォーマーとは何かを理解することが重要です。通常のトランスフォーマーは、入力系列を理解するためのエンコーダ(encoder)と、そこから新しい系列を生成するデコーダの2つの部分から構成されます。しかし、Llamaのような言語モデルでは、自己回帰型生成(autoregressive generation)を行うために、デコーダ部分のみが使用されます。これは、一語ずつ前の情報に基づいて次の語を予測する処理になっており、文章生成に適したアーキテクチャです。
このような構造は、GPTシリーズやLlamaシリーズ、さらにはChatGPTのような人気のある大規模言語モデルに共通しています。したがって、これを自分で構築・応用できるようになることは、AI技術を活用したアプリケーション開発の可能性を大きく広げてくれます。
モデル構成の基本
デコーダ専用のトランスフォーマーモデルの構築に必要な基本的要素について見ていきましょう。主な構成は以下の通りです。
1. トークンの埋め込み(Token Embedding)
最初のステップは、文章の単語などの入力データをモデルが理解可能なベクトルに変換する作業です。通常、この過程ではボキャブラリのサイズと埋め込みの次元数を設定して、各トークンをベクトルにマッピングする層(embedding layer)を導入します。
2. ポジショナルエンコーディング(Positional Encoding)
トランスフォーマーは系列の順番情報を扱う能力を持っていないため、単語の順序を明示する情報が必要になります。これを補うのがポジショナルエンコーディングです。自己注意(self-attention)機構がどの単語がどの位置にあるかを理解するための助けになります。
3. 自己注意層(Self-Attention Layer)
トランスフォーマーの中心的な仕組みがこの自己注意です。入力の各単語が、他の単語との関係性を動的に学習し文脈を把握します。特に、デコーダのみのモデルでは因果マスク(causal mask)という手法が適用され、未来の語にアクセスできないようにすることで、自己回帰的な生成が可能になります。
4. フィードフォワードネットワーク(Feedforward Network)
自己注意の後に入る小さなニューラルネットワーク部分では、各トークンの特徴量をさらに変換・拡張します。これらは通常、ReLUやGELUのような非線形関数を用いて表現力を高めます。
5. 正規化とドロップアウト(Normalization and Dropout)
過学習を防いだり、学習の安定性を確保するために、各層にはレイヤーノルム(layer normalization)やドロップアウトが導入されます。
6. 出力層(Output Projection)
最終的に、それぞれの埋め込まれたベクトルを元のボキャブラリにマッピング(線形変換)して、次のトークンの予測確率を求める出力層が用意されます。
PyTorchでの実装の考え方
記事では、こうした構成要素を分かりやすくPyTorchで実装する方法も紹介されています。特に、モデルを構成する各ブロックをクラスとして定義し、小さなユニットの組み合わせで全体のアーキテクチャを作っていく流れは非常に参考になります。
以下は実装の主な構成要素です。
– TokenEmbedding:入力トークンをミニベクトルに埋め込む
– PositionalEncoding:位置情報を加えたベクトルを生成
– MultiHeadAttention:複数の注意ヘッドを使う自己注意機構
– FeedForward:2層の全結合ネットワークを用いた非線形変換
– DecoderBlock:上記要素を組み合わせた1つの変換ブロック
– TransformerDecoder:複数のDecoderBlockを積み重ねた本体
– OutputLayer:ボキャブラリへの出力を生成する線形層
こうしたモジュール単位の設計は、機能の把握と再利用性の観点でも優れており、初心者や研究者にとっても構築・改良をしやすい構造となっています。
学習プロセスと最適化
モデルが完成したら、次は訓練のフェーズに進みます。ここで重要になるのは、効果的な学習を行うための損失関数と最適化手法です。
– 目的関数(loss function):クロスエントロピー損失を用いて、予測トークンと正解トークンの誤差を最小化します。
– オプティマイザー:AdamWなどの最適化アルゴリズムが効果的に使用されています。
– 学習率スケジューラー:warm-upステップを設けたスケジューラを導入することで、学習初期の安定性を確保することが可能です。
小さなデータセットを使って学習を試すことも容易で、特定のドメインや目的に合わせた微調整(ファインチューニング)を行うことができます。
出力の生成 ― 自然な文章を作る工夫
モデルの性能を実感するには、実際にテキストを生成させてみるのが一番です。記事では、次のような生成手法を紹介しています。
– グリーディデコード:もっとも確率の高い単語を順に選ぶ単純な手法
– トップkサンプリング:確率上位k個の候補からランダムに選択することで多様性を獲得
– トップp(nucleus)サンプリング:一定以上の累積確率をもつ候補から選ぶ自然な生成方式
これらは生成される文章の自然さ、創造性などに大きく影響を与えるため、目的に応じた選択が求められます。
応用と展望
デコーダのみのトランスフォーマーモデルは、その使用範囲に広がりがあります。例えば以下の用途が挙げられます。
– 会話システムやチャットボット
– 物語やニュース記事の生成
– プログラムコードの自動生成
– 言語翻訳や要約
Llamaシリーズの成功によって、こうしたモデルが大規模なデータに基づいて訓練されるケースが増え、今後ますます多様な分野への応用が期待されています。加えて、オープンソースの普及により、個人や小規模チームでも独自の言語モデル開発に取り組みやすくなっています。
まとめ
Llama-2やLlama-3のような先進的なトランスフォーマーモデルを学ぶことは、AI技術の最新潮流を理解し、応用する大きな一歩です。デコーダ専用の設計は、言語生成において効率的かつ高性能な構造を提供しており、自然な文章生成には欠かせない技術となっています。
本記事を通じて、トランスフォーマーの基本的な動作原理から、実装・学習・応用までの流れを理解する助けになれば幸いです。これを機に、オリジナルの言語モデルを作成する挑戦をしてみてはいかがでしょうか。自分が設計したモデルが自然な対話や創作を可能にするというのは、AIと人間の創造力が共に未来を切り開く象徴的な取り組みでもあります。