データ分析の世界は日々進化を遂げており、その中でも特に注目を集めているのが「自然言語インターフェース(Natural Language Interface)」の導入です。複雑なSQLクエリを書かずとも、日常会話のような文章でデータベースとのやり取りができるこの技術は、専門的な知識を持たないビジネスユーザーにもデータ活用の可能性を広げてくれます。今回ご紹介するのは、Amazonが公開した「Amazon Athena」と「Amazon Bedrock」上の大規模言語モデル(LLM)を活用し、会話形式でAthenaへのクエリを実行できるインターフェースを構築する方法です。このソリューションは「Amazon Nova」と呼ばれ、Amazonが社内で開発・使用してきた生成AIのベストプラクティスを詰め込んだサンプルアプリケーションとなっています。
この記事では、Amazonが提案するソリューションの構成から使用しているテクノロジー、導入のメリットまでを詳しく解説していきます。エンジニアやデータアナリストはもちろん、日々の業務でデータ分析を必要とする全てのビジネスパーソンにとって、限りなく実用的な内容となっています。
Amazon Novaとは何か
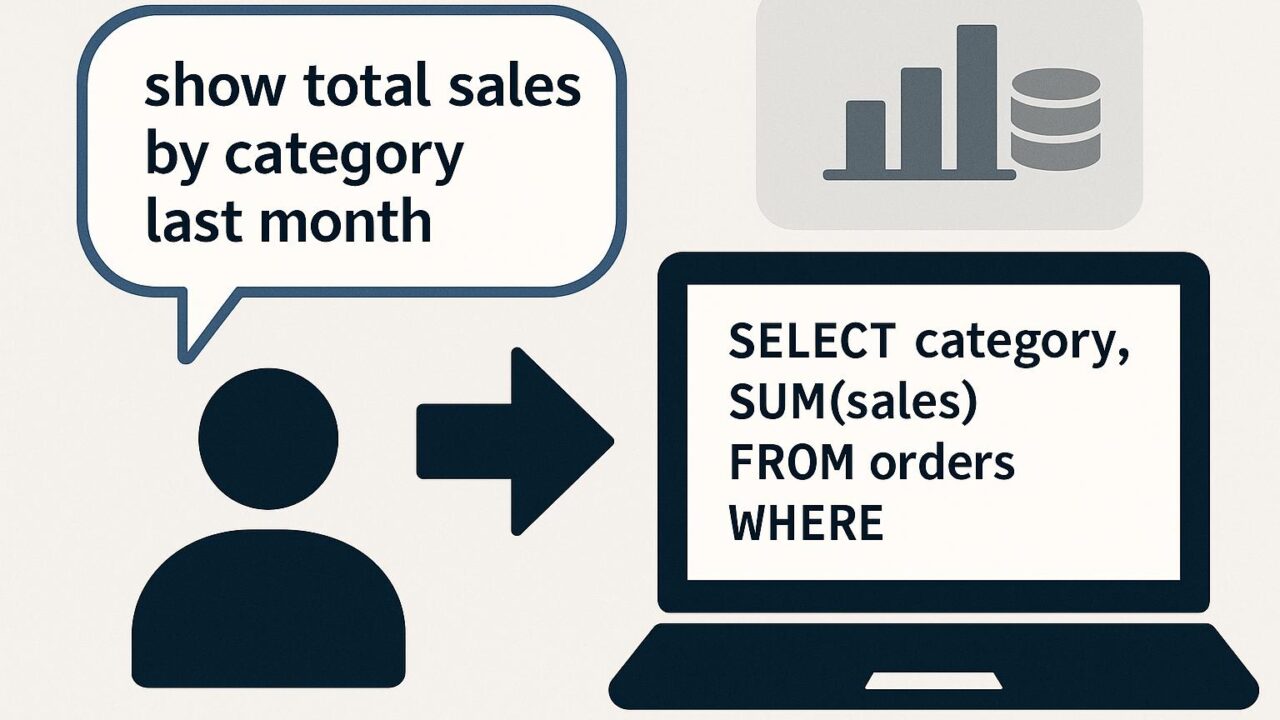
「Amazon Nova」は、自然言語での入力をもとに、Athena用の有効なSQLクエリを生成し、その結果をユーザーに再び自然言語でフィードバックする、いわば「会話型の分析体験」を提供するアプリケーションです。Novaは、Amazonが長年社内で培ってきた生成AIのベストプラクティスをベースにして構築されており、完全にサーバーレスで稼働します。
このアプリケーションは、Amazon Bedrock経由でアクセス可能な大規模言語モデルを活用して、ユーザーが入力した自然文を正確なSQL文に変換します。その際、Athenaに接続されたデータセットから取得したスキーマ情報をもとに、モデルがより精度の高いクエリを生成できるよう工夫されています。さらに生成されたSQLクエリはそのままユーザーに表示されるため、データの取得プロセスがブラックボックスにならず、高い透明性とユーザー学習効果をもたらします。
アーキテクチャ概要
Novaのシステム構成はシンプルながら高度に最適化されており、主なコンポーネントは以下のような役割分担を担っています。
1. ユーザーインターフェース(Amazon CloudFront・S3でホスティング)
フロントエンドはReactベースで構築されており、Amazon CloudFrontとAmazon S3を用いてホストされます。ユーザーはここから自然言語でデータ分析のリクエストを送信します。
2. API層(Amazon API Gateway + AWS Lambda)
フロントエンドからのリクエストはAPI Gateway経由で受け取られ、Lambda関数によって処理されます。このレイヤーが自然言語テキストの解釈や認証・認可機能を担います。
3. クエリ処理とAI統合(Amazon Bedrock + LangChain)
Lambda関数内でLangChainライブラリを用いてプロンプトを整形し、Amazon Bedrockにアクセス、選定されたLLMモデル(AnthropicのClaudeなど)を使ってSQLクエリを生成します。
4. データ取得と処理(Amazon Athena + AWS Glue)
生成されたクエリはAthenaへ送信され、指定のデータセットからクエリ結果を取得。事前にAWS Glueを用いて作成・管理されたカタログ情報もクエリ精度の向上に寄与します。
5. 出力の整形(自然言語での回答生成)
得られたクエリ結果は再びBedrock経由のLLMによって自然言語に変換され、ユーザーに返答されます。これにより、ビジネスユーザーはデータの背景までをより理解しやすくなります。
LLMプロンプト設計の工夫
この強力な対話型システムの裏側では、大規模言語モデルとの対話設計の工夫が光っています。LangChainを活用してプロンプトを論理的に分割し、以下のようなマルチステッププロンプトチェーンを構築しています:
– ユーザークエリの意図理解
– クエリに必要なデータ列、テーブルの特定
– SQLクエリ文の生成
– Athenaへの実行と結果取得
– 返却すべき自然言語文の生成
このプロンプトチェーンにより、LLMに依存しすぎることなく論理的かつ安全にクエリ処理が行えるため、フェイルセーフな対話体験を実現しています。
また、SQL生成と分析結果説明のフェーズはあえて分離されており、これにより処理の透明性と応答内容の精度が向上します。このように、プロンプト設計には実用上の工夫が数多く施されているのが特徴です。
データセキュリティとガバナンス
企業のデータを扱う以上、セキュリティとガバナンスは非常に重要なポイントです。Novaは認証・認可に業界標準のAmazon Cognitoを採用しており、ユーザー単位でAthenaへのアクセス権限を制御可能です。さらに、生成されたSQL文自体もLambda関数内で検査・sanitizeされるため、不正なクエリ実行のリスクも低減されています。
また、Athena側では既存のIAMベースのアクセスコントロールをそのまま活用でき、監査ログもCloudTrailによって取得可能となっています。こうした設計により、業務利用に耐える堅牢なアーキテクチャが実現されています。
導入のメリット
このような会話型インターフェースを導入することで得られる主なメリットには以下のようなものがあります:
– 非エンジニアでもデータにアクセス可能になり、意思決定の迅速化が図れる
– 複雑なクエリ構文を覚えなくても良いため、教育コストが削減される
– クエリ生成の透明性が高く、運用リスクを軽減できる
– LLMの進化に伴い、継続的に対話精度が向上する可能性がある
さらに、インフラの全体像がサーバーレスで構築されているため、初期構築コストも抑えることができ、DevOpsにかかる日々の負荷も最小限で済みます。
将来の展望と可能性
Amazon Novaによる会話型インターフェースは、現時点でも非常に実用的なソリューションですが、この先もさらなる進化が見込まれています。より高度な意図解釈や、ビジュアルなデータ出力への拡張、マルチターン会話(質問の文脈を維持しつつやり取りを続ける能力)なども今後追加されていく可能性があります。
そして何より、こうした自然言語インターフェースは、形式的なクエリ言語という壁を取り払い、真に「全社員がデータドリブンで動ける」世界の実現に向けた強力な一歩となります。
まとめ
Amazon Novaは、生成AIとクラウド型分析サービスを活用し、誰もが簡単にデータへアクセスし、その知見をビジネスに活かすための画期的なソリューションです。そのシステムはセキュアかつ柔軟で、カスタマイズやスケールアップも容易。企業におけるデータ利活用の民主化を加速させる大きな力となることでしょう。
もしあなたが、ビジネスの中でより多くのメンバーにデータ分析の力を届けたいと考えているなら、このAmazon Novaの構築ガイドを一度試してみる価値は十分にあります。自然言語で対話するだけで、データが自動で答えをくれる——そんな未来が、もうすぐそこまで来ています。