強化学習における大規模言語モデルの性能向上手法「Cooper」の新提案
大規模言語モデル(Large Language Models, 以下LLMs)の急速な進歩と普及に伴い、その訓練法や応用手法が注目を集めています。特に、強化学習(Reinforcement Learning, 以下RL)を用いた「報酬モデル(Reward Model, RM)」と「方策モデル(Policy Model, PM)」の学習は、言語モデルの性能を飛躍的に高めるうえで極めて重要です。こうした手法の代表例として、RLHF(Reinforcement Learning from Human Feedback)が挙げられます。RLHFは人間のフィードバックを活用してモデルを望ましい出力へと導きますが、その中で報酬モデルと方策モデルは別々に最適化されることが一般的でした。
しかし、報酬モデルと方策モデルは密接に関連しているにもかかわらず、従来の手法ではそれぞれが別建てで訓練されていたため、最終的なモデル性能において非効率が存在していたのも事実です。こうした課題に着目して新たに提案された手法が、「Cooper(Co-Optimizing Policy and Reward models)」です。この記事では、Cooperがどのようにこの問題に取り組んでいるのか、その仕組みと利点について分かりやすく紹介します。
報酬と方策の「共同最適化」という新アプローチ
Cooperの最大の特徴は、報酬モデル(RM)と方策モデル(PM)を並行して、さらには相互に影響を与えながら訓練していくという点です。これまでのアプローチでは、まず報酬モデルを固定し、その後にそのモデルを教師として用いて方策モデルを学習していました。しかしこの方法では、報酬モデルのバイアスや過剰適合が方策モデルに悪影響を与えるリスクがありました。
これに対してCooperでは、RMとPMを同時に、もしくは交互に最適化することで、一方が進化すればもう一方も自動的にその変化に応じた学習が行われる構造となっています。これにより、PMが最適な応答を生成するように進化する過程で、それに合わせてRMもより良いフィードバックを提供できるように更新され、両者が高いパフォーマンスを発揮できる状況に導かれます。
この共同最適化を可能にしたのは、「正則化項」と「最適化アルゴリズム」の設計です。システムが過剰に適合しすぎないように工夫されており、両者が互いに強化し合う良循環を生み出す設計になっています。
Cooperの訓練構造とそのメカニズム
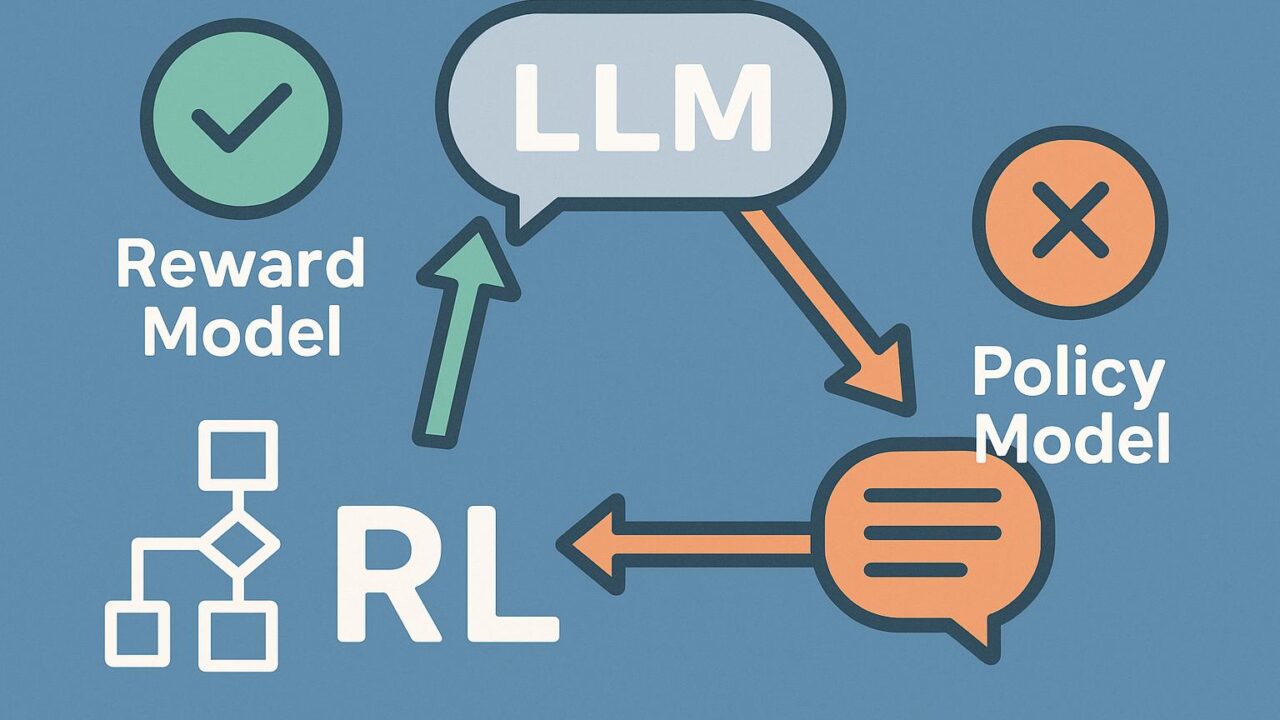
Cooperの学習プロセスでは、まず初期状態としての報酬モデルと方策モデルが用意されます。ここで用いられるのは、すでに基本的な学習がなされたプロンプト応答形式のLLMです。次に、複数の選択肢(例:「応答A」「応答B」)を生成し、それらに対して報酬モデルがスコアリングを行います。従来の方法であれば、ここで最もスコアの高い生成出力を選んで、それを方策モデルが模倣するという形式が取られてきました。
しかし、Cooperではここからさらに一歩進みます。報酬モデルによるスコアリングと、方策モデルの出力分布の間にある整合性や乖離を評価し、それを元にフィードバックループを形成します。このループでは、PMがより良い出力を生成するために学習すると同時に、RMもより一貫性を持った報酬スコアを提供できるように進化していきます。このプロセスはステップごとに繰り返され、最終的にはPMとRMが相互に最適状態に近づいていく構造になっています。
実験結果が示すCooperの優位性
この手法がどれほど有効かを検証するために、複数のベンチマークタスクで既存の RLHF モデルとCooperを比較する実験が行われました。ベンチマークには、ユーザーの好みに合致する応答をどれほど高い精度で生成できるかを測定するタスクが含まれていました。結果として、Cooperを適用したLLMは、従来のRLHF手法に比べて一貫性が高く、自然言語応答の質も高いという評価を得ています。
さらに、報酬モデルの性能にも注目すべき向上が見られました。従来の報酬モデルは固定されていたため、学習過程で発生するノイズやバイアスをそのまま引きずる傾向がありましたが、Cooperでは方策モデルと常に適応的に学習するため、より信頼性の高いスコアが提供できるようになっています。
また、CooperはPMの過学習を防ぐ役割も果たしています。これにより、現実的な設定でも高い一般化性能を持つLLMの訓練が可能になりました。
実用性と今後の展望
Cooperがもたらす最大の利点は、モデルパフォーマンスの向上だけではありません。実運用において極めて重要なのはモデルの「調整可能性」と「頑健性」です。ユーザーや運用者が望む出力の形式や内容、あるいは言語モデルの倫理性に対する制御能力が高まることで、機械生成のコンテンツに対する信頼性が向上します。
また、生成モデルを用いた対話エージェントや検索サービス、さらには教育・医療・法律分野にまで応用が広がる可能性がある中で、対話出力の品質や公正性、透明性を保つことが求められています。そうした時に、Cooperのように報酬モデルと方策モデルの学習を高度に統合したアプローチは、より高度なAIモデルトレーニングの基盤となりうるものです。
今後の発展としては、Cooperのフレームワークを他のアーキテクチャにも応用する研究や、報酬モデルに人間のフィードバックだけでなく多様なメタデータやセンサーデータを取り入れることでさらなる精度向上を図る試みが期待されています。
まとめ:一歩進んだLLMの強化学習へのアプローチ
強化学習と大規模言語モデルの組み合わせは、近年急激に進化してきた分野のひとつです。その中でCooperは、報酬モデルと方策モデルの「共同最適化」という観点からこれまでにないアプローチを提示しました。この手法の革新性は、ただ性能が向上するというだけでなく、モデル全体の信頼性や調整可能性を高めることにあります。
AI技術の応用が日々拡大する中で、よりユーザーに寄り添った、正確かつ調和の取れた出力を持つLLMの開発は、社会的にも重要な課題です。Cooperはその道を切り開く新たな鍵となる可能性を秘めており、今後の研究と応用が非常に楽しみな技術の1つです。