自然な言語の壁を越えて:Transformerモデルを用いた翻訳技術の進化
私たちは世界中で日々さまざまな言語を使用しています。インターネットを介して情報が飛び交う現代社会において、異なる言語間の壁を越える翻訳の技術は、私たちのコミュニケーションと理解を劇的に広げる鍵となっています。特に深層学習技術の進化は、言語翻訳の分野にも大きな変革をもたらしつつあり、その中でもTransformer(トランスフォーマー)というモデルは、まさにその中心的存在と言えるでしょう。
本記事では、「Building a Transformer Model for Language Translation」と題された情報源に基づき、Transformerモデルの概要、構築方法、そしてなぜこのモデルが優れているのかについて、応用事例を交えながら解説していきます。
Transformerとは何か?
Transformerモデルは、自然言語処理の分野における革新の一つです。それ以前の翻訳システム、多くがRNN(リカレントニューラルネットワーク)やLSTM(長・短期記憶)に基づいていたモデルと比べ、Transformerはまったく異なる構造を持っています。最大の特徴は「自己注意機構(Self-Attention)」にあります。これは、文中の単語が他の単語にどれだけ注目すべきかを数値的に表現し、意味的に重要な関係を考慮することができる仕組みです。
この技術により、Transformerは文全体のコンテキスト(文脈)をきわめて高精度で捉えることが可能になりました。その結果として、かつてないほど自然な翻訳ができるようになり、多言語間の相互理解がよりスムーズに行えるようになったのです。
Transformerモデルの主な構成
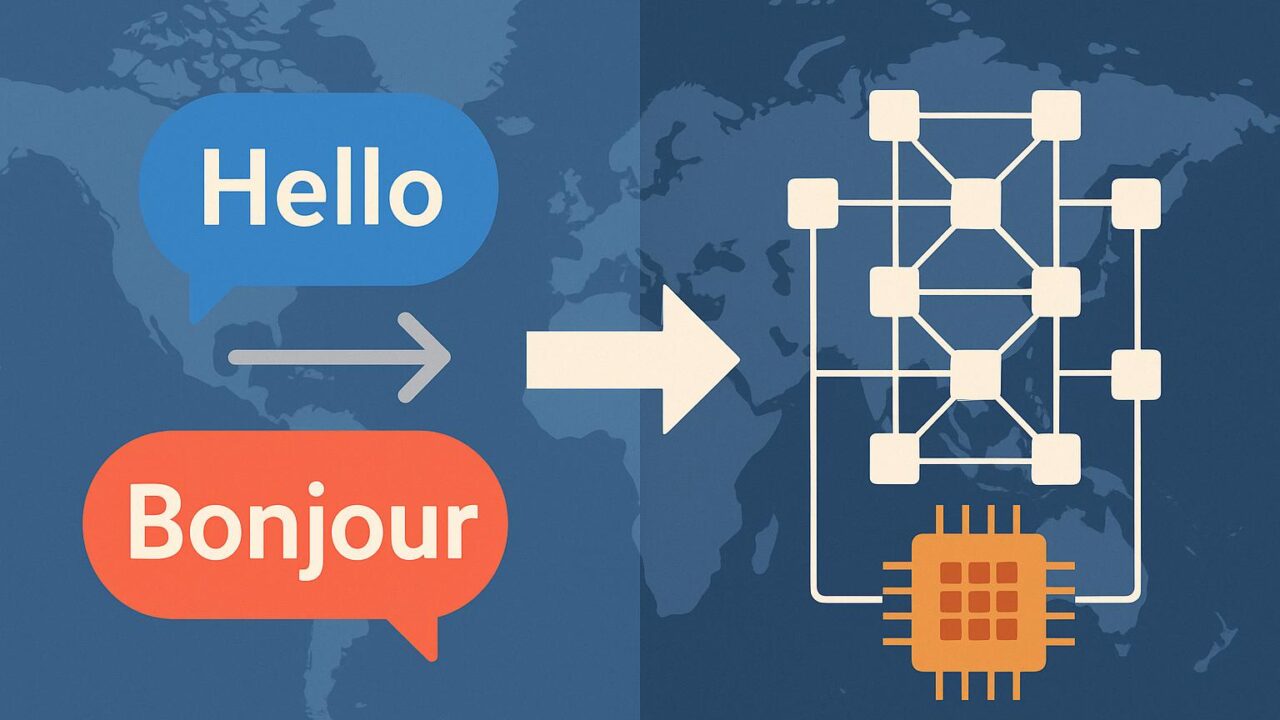
Transformerモデルは、大きく分けてエンコーダとデコーダの2つのブロックから構成されます。
1. エンコーダ(Encoder):入力された文(例えば英語の文)を内部的なベクトル表現に変換します。ここでは、複数のエンコーダレイヤーが使用され、それぞれが自己注意とフィードフォワードネットワークを含む仕組みとなっています。
2. デコーダ(Decoder):エンコーダで得られた情報を元に、ターゲットとなる別の言語(例えばフランス語など)の文を出力します。デコーダも同様に多層構造をもち、自己注意とエンコーダとの注意層(エンコーダ・デコーダアテンション)を含みます。
このような構成によって、Transformerは入力と出力の間の関係性を非常に柔軟かつ正確にモデル化することができるのです。
モデル構築のステップ
実際にTransformerモデルを構築するためのステップは、以下のような流れになります。
データの準備
翻訳モデルの開発においては、元となる文章(入力言語)と対応する翻訳(出力言語)の対になったデータセットが必要です。通常は、十分な文量と多様な表現が含まれる公開データセット(たとえばTatoeba、Europarl、WMT等)が用いられます。
このステップでは、入力言語とターゲット言語をそれぞれトークナイズ(単語や文節への分割)し、あらかじめ用意した語彙リストに変換する工程が重要です。また、文に順序の情報を付与するため、位置エンコーディング(Positional Encoding)という手法が使われます。
Transformerアーキテクチャの実装
Transformerの構造を実装するには、深層学習フレームワーク(たとえばTensorFlowやPyTorch)を使用します。エンコーダとデコーダを複数層に積み重ねる設計が基本となります。
重要なのは、自己注意層やマルチヘッドアテンションの仕組みを正確に実装することです。これらの層では、単語間の関係性を多面的に捉えるため、複数の注意ヘッド(情報の視点)を並列に用いて、より豊富な表現力を実現しています。
トレーニングと評価
データとモデルの設計が整ったら、次は教師あり学習を用いてモデルを訓練します。この段階では損失関数—多くの場合クロスエントロピー損失—を最小化するように、モデルの重みを最適化していきます。
トレーニングには、GPUやTPUなどの計算資源が求められる場合があり、特に大規模なデータセットを使う際には高速な並列処理が鍵となります。
モデルが訓練されたら、開発用データやテストデータでその性能を評価します。BLEUスコアなどのメトリクスを使って、どれくらい正確に翻訳できているかを数値化します。
Transformerの強みと限界
Transformerの最大の強みは、文の中のすべての単語が互いにどのように関わっているかを柔軟に学習できる点です。この性質により、文脈の多義性を含むような、複雑な構文も自然に翻訳できる能力を備えています。
加えて、RNNベースのモデルに比べて並列処理がしやすいため、トレーニングの効率が高く、大量のデータ処理に適しています。これがTransformerが広く採用されているもう一つの理由です。
しかしながら、唯一の欠点は、巨大な数のパラメーターを持つため、計算資源の消費が大きく、モデルの訓練や運用に高性能なインフラ環境が求められることです。
応用と可能性
Transformerモデルは機械翻訳だけにとどまらず、あらゆる自然言語処理のタスクで導入が進んでいます。たとえば、文章要約、質問応答、文書分類、さらには音声認識や画像キャプション生成など、その応用範囲は年々広がっています。
GoogleのBERTやOpenAIのGPTシリーズといった大規模言語モデルも、すべてTransformerのアイディアから生まれた技術です。つまりTransformerは、単なる一つの手法というよりも、自然言語処理における「基本的な構造要素」としての地位を確立しているのです。
私たちの身の周りでは、すでに多くの場面で自動翻訳技術が活用されています。観光地での案内表示、オンライン上のショッピング支援、国際的なビジネス交渉など、その恩恵は計り知れません。そしてTransformerモデルは、その中核にある最先端のテクノロジーです。
まとめ
Transformerモデルは、機械翻訳の分野に新しい可能性をもたらし、異なる言語を話す人々の橋渡しとして重要な役割を担っています。その構造はエンコーダ・デコーダによる自己注意機構に基づいており、文脈を豊かに理解できる優れた性能を持っています。
将来的には、さらに高度なマルチリンガル対応や、より効率的な軽量モデルの開発が期待されます。言語の違いに縛られないグローバルなコミュニケーションが、より自然に、より広範に広がる未来は、そう遠くないかもしれません。
この技術の進化に引き続き注目しつつ、その恩恵を最大限に活用するための知識を深めていくことが、私たち一人ひとりに求められているのではないでしょうか。