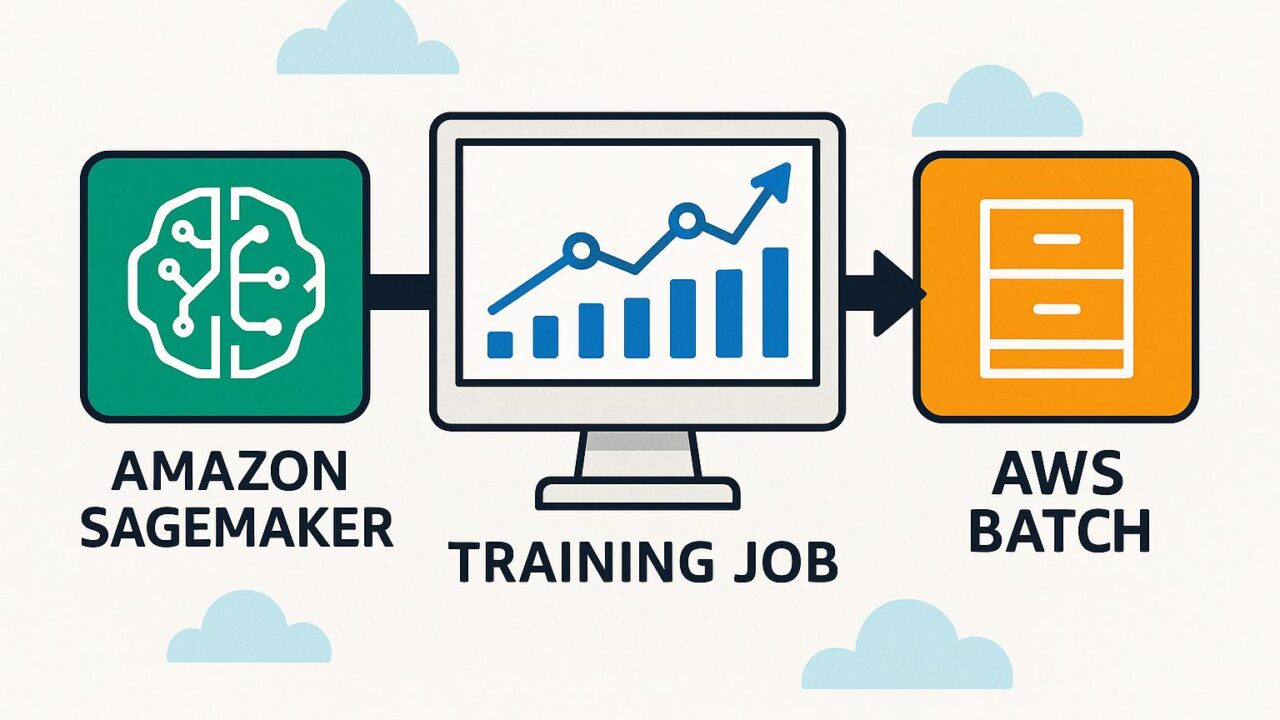
Amazon SageMakerのトレーニングジョブに対するAWS Batchのサポートが開始されたことで、多くの機械学習エンジニアやデータサイエンティストにとって画期的な新機能が登場しました。この発表により、機械学習のトレーニングジョブの管理や実行方法がさらに柔軟かつ効率的になります。本記事では、Amazon SageMakerとAWS Batchの連携によって得られるメリットや利用方法について、分かりやすく解説していきます。
Amazon SageMakerとは?
Amazon SageMakerは、AWSが提供するフルマネージドの機械学習サービスです。モデルの構築、トレーニング、チューニング、デプロイといった一連の機械学習プロセスを簡素化・自動化するための多機能なプラットフォームです。機械学習の専門知識が深くなくても、インフラを意識せずに効率的な開発と検証が行えるため、多くの企業や研究者が利用しています。
従来、SageMakerのトレーニングジョブは、マネージドなSageMakerインフラストラクチャ上で主に実行されていました。これは非常に便利な反面、リソースコストやカスタム性の面でさらなる柔軟性を求める声もありました。そうしたニーズに応える形で、AWS Batchサポートが加わったのです。
AWS Batchとは?
AWS Batchは、大規模なバッチコンピューティングのジョブスケジューリングとリソース管理を行うサービスです。開発者や研究者は、マネージドインフラストラクチャ上で効率的なバッチジョブの実行が可能となり、コンピューティングリソースの確保や運用管理に煩わされることなく、コンピュート集約的な処理を実施できます。
AWS Batchは、さまざまな仮想化環境(EC2インスタンスおよびAWS Fargate)に対応し、オンデマンドあるいはスポットインスタンスを活用することで、コストパフォーマンスに優れたジョブ実行を実現しています。
SageMakerとAWS Batchの連携とは?
今回発表された新機能により、SageMakerのトレーニングジョブをAWS Batchによって実行できるようになりました。この連携は、機械学習モデルをトレーニングする際のコンピューティングリソースのさらなる柔軟性をもたらします。
例えば、既にAWS Batchを使ってコンピューティングワークロードを処理している場合、同じインフラストラクチャ上で機械学習モデルのトレーニングも実行できるようになります。これにより、インフラの統合、リソースの共用、さらにコスト管理の一元化が可能になります。
主なメリット
1. 柔軟なインフラ構成とコスト最適化
AWS Batchを使うことで、ユーザーはEC2オプションをカスタマイズしやすく、オンデマンドインスタンスやスポットインスタンスを選択することにより大幅なコスト削減が見込めます。トレーニングジョブは特に長時間にわたるものも多く、コスト効率は現場にとって重大なテーマです。AWS Batchを活用することで、限られた予算内でより多くの実験を行うことができ、モデルの精度向上にも寄与します。
2. 高いスケーラビリティ
AWS Batchは、数百から数千のジョブを効率よくスケジュール可能な高スケーラビリティを備えています。トレーニングタスクの規模が急激に増えた場合でも、リソース管理の柔軟性が確保されており、迅速な拡張が可能です。これにより、実験のスピードアップとタイムリーなインサイトの獲得が期待できます。
3. カスタム環境の活用
AWS Batchでは、独自に設計されたDockerコンテナを使って環境を構築することが可能です。これにより、特定のライブラリや依存関係、カスタムバージョンのソフトウェアが必要なトレーニングタスクに対応した環境構築が容易になります。研究や産業用途など、環境要件が厳しいプロジェクトにおいても、柔軟な環境設定が可能となりました。
4. インフラの再利用性とDevOpsとの統合
すでにAWS Batchを利用したバッチ処理パイプラインが存在する場合、それを踏襲して機械学習ジョブを統合できることも大きな利点です。また、既存のCI/CDパイプラインやモニタリングシステムと連携させることで、トレーニングジョブの自動化、可視化、ログ管理もスムーズに行えます。
利用方法の概要
SageMakerでのトレーニングジョブをAWS Batchで実行するためには、SageMaker Python SDKを使って所定の設定を行うだけで済みます。新たに追加された“TrainingJobDefinition” APIフィールドを使い、ジョブタイプとして“batch”を選択します。その際、Dockerイメージ、コマンドラインの引数、入力データの場所、出力先バケットなどを定義します。加えて、AWS Batchジョブ用のジョブキューやコンピュート環境の構築も必要となりますが、これらは一度セットアップすれば以後のトレーニングジョブに再利用可能です。
また、Amazon SageMaker Studio、SageMaker Python SDK、あるいはBoto3といった様々なインターフェース経由でこのトレーニング実行が可能となっており、開発環境やスキルレベルに応じた柔軟な選択肢が提供されています。
ユースケースの一例
例えば、製薬企業が新薬開発の過程で生成モデルを使って化合物の構造を探索する場合、大量のシミュレーションが必要になることがあります。こうした状況で、高性能なGPUインスタンスを活用した並列トレーニングが必要になるものの、稼働率が非常に不安定であるためサービスのコストが課題となります。
このようなシナリオでAWS Batchを用いたSageMakerトレーニングジョブを活用すれば、最もコスト効率の良いタイミング(例えばスポットインスタンスの料金が下がっているとき)で計算資源を使い、トレーニングを進めることが可能になります。これにより、コストと精度のバランスを取りながら研究開発が加速されます。
また、モバイルアプリのパーソナライズモデルをトレーニングする場合も、ユーザーの行動履歴など非構造データの処理が必要となります。このようなデータセットの準備とトレーニングを、企業の既存のバッチパイプラインと一元管理できるようになるため、運用の簡素化につながります。
今後に向けた期待
この新機能は、AWSの柔軟でスケーラブルなサービス群の統合展開の一端を示しています。Amazon SageMakerとAWS Batchの連携は、インフラの選択肢を拡大し、研究者やエンジニアが求める”自由度”と”効率性”を実現しています。
今後、より多くの機械学習タスクがバッチ処理に適用可能になるだけでなく、分散トレーニングや自動ハイパーパラメータチューニングとの組み合わせによって、より高度なインテリジェンス開発が期待されます。
さらに、環境への配慮の観点から、使用リソースの最適化は重要なテーマとなっており、AWS Batchによる動的なリソース調整機能は、持続可能なAI開発の一助にもなるでしょう。
まとめ
AWS BatchのAmazon SageMakerトレーニングジョブへの対応は、単なる機能拡張ではなく、機械学習のライフサイクル全体を見据えた効率化を可能にする大きな一歩です。個々のトレーニングジョブに対して、最適なリソースを柔軟に選択し、コストとパフォーマンスのバランスを自由に設計できるようになります。
すでにAWS Batchを利用しているユーザーにとっては、既存のバッチインフラの再利用ができる点で魅力的ですし、SageMakerユーザーにとっても、広がり続ける選択肢の中で、用途に最適な実行環境を選べるという自由度が得られます。
今後もAWSは、機械学習やクラウドインフラの包括的な進化を牽引していくことが期待されており、その一端をユーザー自身が手に取って体験できる新機能として、今回の連携機能が持つ意義は非常に大きいといえるでしょう。