Amazon Novaを活用した構造化出力の実現:開発者向けガイド
近年、生成系AIの進化は目覚ましく、多くの領域での活用が加速しています。自然言語処理における大規模言語モデル(LLM)は、人間と同等の文章理解や生成を実現するようになり、チャットボットやコンテンツ生成、コーディング支援ツールなど多岐にわたる用途で実用化が進んできました。
その一方で、LLMの自由なテキスト生成能力は便利である一方、期待する構造に沿わない出力が得られる可能性も否定できません。特定のアプリケーションでは予測される出力に厳密な構造やフォーマットを求められる場面があり、「構造化出力(structured output)」はこのようなニーズに応えるための重要な技術となっています。
このような背景のもと、Amazonが提供する新しいマネージドサービス「Amazon Nova」は、構造化された出力をより簡単に実現するための機能を提供しています。本記事では、開発者やビルダーがAmazon Novaを利用して効率的かつ正確に構造化出力を得るためのアプローチや、その背後にある仕組みに焦点を当て、実際のユースケースを交えながらその利便性と可能性を探っていきます。
Amazon Novaとは?
Amazon Novaは、Amazon Bedrockの一部として提供されている新しい生成AIサービスで、開発者が高品質な生成AI機能を安全かつスケーラブルに利用することを可能にします。Novaは独自に訓練された大規模言語モデルをベースとしており、一般的な質問応答や文章生成から、より制約のある構造化出力まで対応可能です。
Amazon Novaの強みの一つに、「目的に特化した出力制御機能」があります。これにより、開発者が出力の形式や内容に一定の制限を設けることで、ビジネスロジックと整合性のある応答を獲得しやすくなります。
構造化出力とは何か?
一般的に、生成AIモデルが出力するコンテンツは自由形式の自然言語ですが、ある種のアプリケーションでは明確な構造を必要とします。たとえば:
– JSON形式で情報を出力するAPI
– 固定のフィールド(氏名、住所、年齢など)を含む登録フォーム
– 意見やレビューなどを分類するレポートフォーマット
– セマンティックなタグ付けされた記事コンテンツ
このような場面では、LLMの柔軟な出力能力に頼りつつも、出力を構造化して扱いやすくしなければなりません。しかし、LLMは自在な自然言語での応答に特化しており、出力を完全に厳密な構造に従わせるのは容易ではないという課題がありました。
ここでAmazon Novaが提供する「構造化出力」機能が、新たな解決法となって登場します。
Structured Outputの主な機能
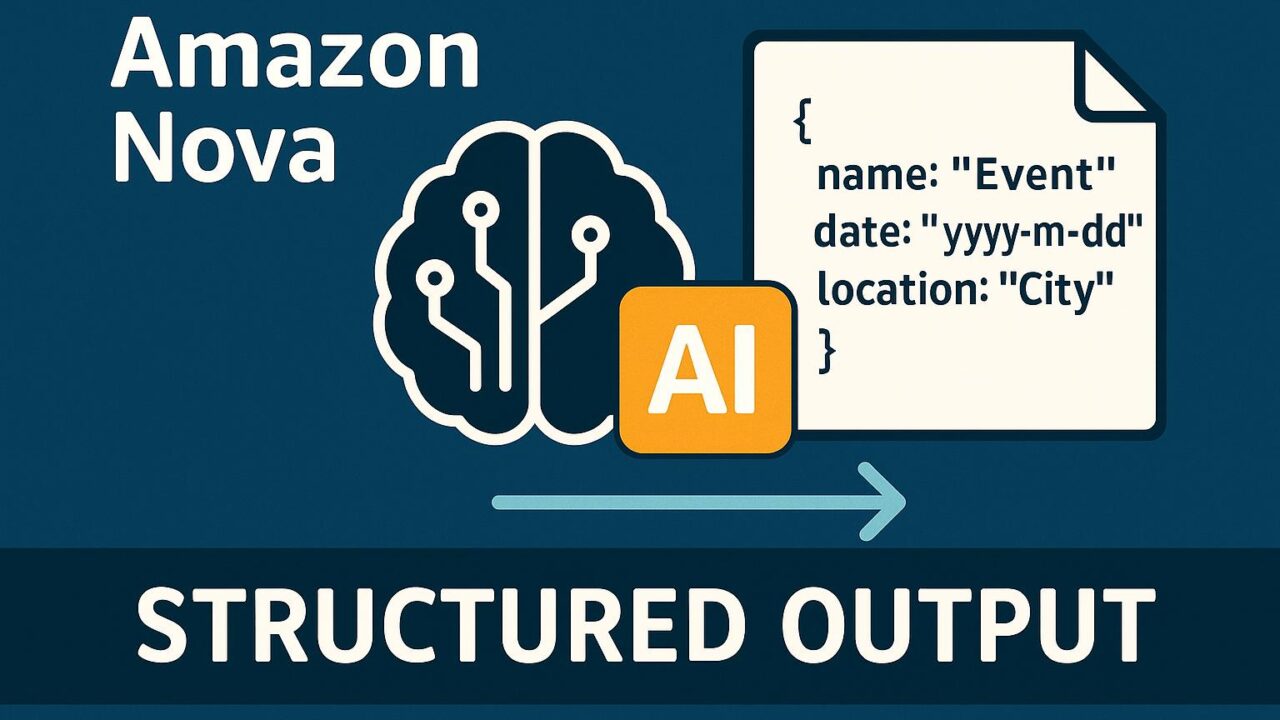
Amazon NovaのStructured Output機能は、ユーザーが出力のスキーマ(構造)を事前に定義することで、LLMの回答を希望形に調整することを可能にします。開発者はタスクに応じて必要な出力フォーマットを指定することで、モデルの応答を設定された枠内に収めることができます。
スキーマは一般的にJSON Schema構文をもとに記述され、これによりAPI応答やデータベースへの連携を容易にします。
たとえば以下のようなスキーマを定義することができます:
{
“type”: “object”,
“properties”: {
“event_name”: { “type”: “string” },
“date”: { “type”: “string”, “format”: “date” },
“location”: { “type”: “string” }
},
“required”: [“event_name”, “date”, “location”]
}
このように定義された構造に従って、モデルは「2024世界観光サミット」「2024-10-21」「京都」などの情報を、各フィールドに即して出力するため、結果がシステムで確実に処理されやすくなります。
Schema-based prompting:プロンプトの工夫
Amazon Novaでは、構造化出力を行うために「schema-based prompting」と呼ばれる戦略を採用しています。これは、プロンプト(命令文)に出力スキーマの情報を組み込むことで、モデルに明確な回答形式を意識させるものです。
単に「カンファレンスに関する情報を提供して」と言うのではなく、「次のスキーマに基づいてカンファレンス情報を答えてください」というような形でプロンプトを提示することで、モデルは出力の構造をより正確に遵守します。
また、Nova専用の推論エンジンでは、スキーマとの整合性が取れなかった場合にリトライして再生成を行うメカニズムも備わっています。これにより、必要に応じて複数回試行を行い、構造に準拠した結果を得るという妥当性を担保する機能が働きます。
活用事例:自由記述によるフォーム入力の定型化
企業のカスタマーサポートでは、ユーザーからの問い合わせ内容をテンプレートに沿って分類・整理する必要があります。Novaの構造化出力を使えば、自由形式で送られてきたテキストを以下のような構造化されたフォーマットに変換できます。
{
“customer_name”: “佐藤太郎”,
“issue_category”: “配送の遅延”,
“urgency”: “高”,
“summary”: “商品が発送予定日を過ぎても届いていない”
}
このように整形されたデータは、次のワークフローに容易に統合でき、オペレーターの負担を大幅に軽減することが可能です。
活用事例:自動記事要約とメタ情報の抽出
メディア企業やブログ運営者にとって、記事内容から要約を作成し、SEOを意識したキーワードの抽出やカテゴリ分類を行う作業は非常に手間がかかるものです。Amazon Novaの構造化出力によって、記事本文を入力とし、以下のようなメタ情報を自動的に構成することができます。
{
“summary”: “本記事ではAmazon Novaの構造化出力機能について解説し、開発者への利点を示している。”,
“keywords”: [“Amazon Nova”, “構造化出力”, “生成AI”],
“categories”: [“AI”, “開発者ツール”]
}
この情報は自動でCMSやSEOツールと連携でき、業務の効率化と品質向上に貢献します。
活用事例:商品レビューの定型化
Eコマースプラットフォームで取得されるレビューは主観的かつ多様ですが、構造化出力によって「満足度」、「評価ポイント」、「改善事項」などに分類することができ、商品改良やマーケティング戦略に役立ちます。
たとえば、あるレビューに対して以下の構造でデータを生成します:
{
“rating”: 4,
“positive_aspects”: [“デザイン”, “使用感”],
“negative_aspects”: [“価格がやや高い”]
}
このような分析により、定量化されたユーザーフィードバックを得ることが可能となるのです。
Amazon Novaと開発者へのメリット
Amazon Novaを構造化出力タスクに活用することで、開発者は以下のような利点を享受できます:
– 柔軟なプロンプト作成による構造化コントロール
– JSON Schema準拠の出力で、既存システムとの整合性が向上
– 自動バリデーションと再生成による高い信頼性
– 定型化データに基づくオートメーションと統合の容易さ
とくに、Bedrockとの統合によりAmazonのセキュリティフレームワークに準拠した環境での運用が可能であり、機密性の高い業務でも安心して使用できる点が重要です。
まとめ:構造を制す者がAI活用を制す
複雑なデータ処理と迅速な意志決定が求められる現代において、LLMは有力なツールとなりますが、真に実用的な成果を得るには、自由な創造性と厳格な整合性のバランスが求められます。Amazon Novaが提供する構造化出力機能は、この課題を効果的に克服するための強力な手段となるでしょう。
生成AIの可能性を最大限に引き出すためには、出力が思い通りの形で得られるかどうかが鍵となります。Amazon Novaでの構造化出力は、ただ便利なだけでなく「信頼性」や「再利用性」を備えた情報への道筋を切り開くものです。開発者、エンジニア、プロダクトマネージャーなど、最新のAI技術を業務に取り入れたいすべての人にとって、Novaは見逃せない選択肢となることでしょう。
生成AIと構造化のハーモニーで、より良いプロダクトとサービスの未来が切り拓かれる――そのスタート地点に、Amazon Novaは立っています。