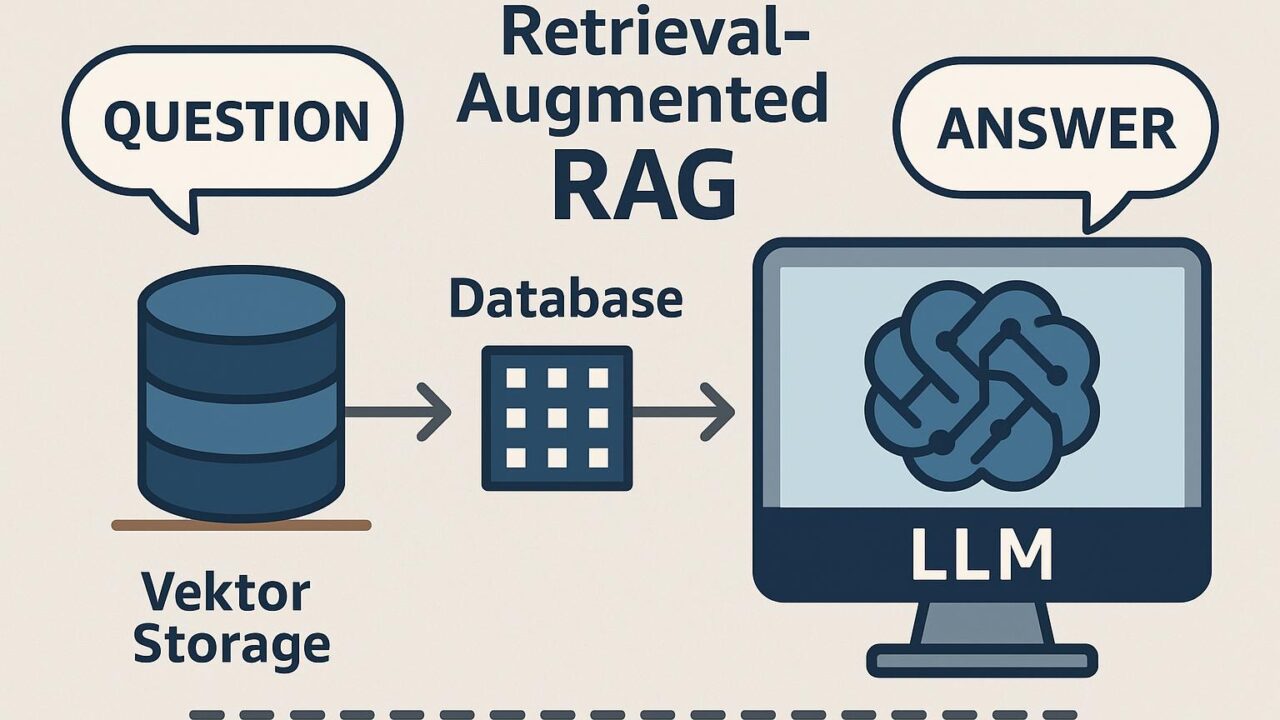
現在、生成AI技術の進歩は目覚ましく、さまざまな分野でその活用が加速しています。特に、質問応答や情報検索における「Retrieval-Augmented Generation(RAG)」のアプローチは、ユーザー体験を飛躍的に向上させる手段として注目されています。本記事では、Amazon Bedrock Knowledge BasesおよびAmazon S3 Vectorsを活用して、コスト効率の高いRAGアプリケーションを構築する方法についてご紹介します。RAGアプリケーションの仕組みや利点、さらにはそれを支えるAWSの最新サービスの活用法を、具体的なユースケースを交えて詳しく解説します。
RAGとは何か?
RAG(Retrieval-Augmented Generation)は、大規模言語モデル(LLM)と外部の情報ソースを連携させることで、より正確で背景知識に基づいた回答を生成する手法です。LLM単体では、トレーニングデータに依存するため、最新情報や専門的な情報には限界があります。RAGは、ユーザーの質問に対して外部のデータストアなどから適切なコンテキスト情報を検索・取得し、それをLLMに与えて回答を生成させることで、より有用で正確性の高いアウトプットを実現します。
Amazon Bedrock Knowledge Basesの特徴
Amazon Bedrockは、さまざまな基盤モデル(Foundation Models)をAPI経由で利用できるサービスであり、開発者はインフラの整備やモデルの管理に時間をとられることなく、迅速に生成AIアプリケーションを構築できます。Bedrock Knowledge Basesは、RAGの実装に不可欠な構成要素であり、外部データへの接続、知識のベクトル化、LLMへの適切な情報提供を自動で行います。
Knowledge Basesを利用するメリットには以下が挙げられます:
– データの取得・変換・インデックス作成などを自動で処理
– 智能なチャンク分割と埋め込み生成
– ベクトル検索による高精度なコンテキスト取得
– セルフホステッドなベクトルデータベースへの柔軟な対応
– コンソールやAPIからの簡単な操作
これにより、エンジニアは複雑なデータ処理ロジックやLLMとの連携部分を意識することなく、迅速にRAGアプリケーションを構築できます。
Amazon S3 Vectorsとの連携
最近追加されたAmazon S3 Vectorsは、RAGアプリケーションに最適化された新しいベクトルストレージオプションです。S3のスケーラビリティと耐久性の高さを活かしながらも、専用のベクトルインデックスを用いた高速な類似検索を実現しています。
S3 Vectorsの特徴は以下の通りです:
– フルマネージドでサーバーレスなアーキテクチャ
– データスキーマやインデックスの定義が不要
– 埋め込みデータはAmazon Titanモデルを利用して自動生成可能
– ベクトルの検索性能とスループットの自動スケーリング
– 外部ベクトルデータベースを保持せず、S3上で簡潔に管理が可能
これにより、多くの開発者にとって、RAGアプリケーション構築の初期コストと運用負荷が大幅に削減されます。
構築のステップ
RAGアプリケーションをAmazon BedrockとS3 Vectorsで構築する際の基本的なステップは以下のようになります:
1. データセットの用意:
ユーザーが求める情報を含む社内文書やFAQ、製品マニュアルなどをAmazon S3に保存します。PDFやTXTなどのフォーマットにも対応しています。
2. Knowledge Baseの作成:
Amazon BedrockコンソールからKnowledge Baseを作成し、データソースとしてS3バケットを指定します。S3 Vectorsを選択することで、これらのデータは自動的に埋め込み生成およびエンベディング処理が実施されます。
3. インデックスおよび検索セットアップ:
Knowledge Baseが自動的にデータをチャンク化し、検索可能なベクトルとしてインデックスします。デフォルトではAmazon Titan Embeddingsを使用することも可能です。
4. アプリケーションとの統合:
APIを通じてアプリケーションからKnowledge Baseを参照し、ユーザーの入力に応じて関連文書の検索結果を取得し、LLMに入力して生成された回答を受け取るというパイプラインを構成します。
ユースケース
Amazon Bedrock Knowledge BasesとS3 Vectorsを使ったRAGアプリケーションは、幅広い業種・用途に適用可能です。たとえば以下のようなシナリオが考えられます:
カスタマーサポート:
既存のFAQやサポートドキュメントをKnowledge Baseにアップロードし、チャットボットやサポートオペレーターがより正確で一貫性のある回答を迅速に提供できるようになります。
法律・契約関連の文書照会:
大量の法律文書や契約書を保持している場合、問い合わせに対して自動で内容を検索し、関連する条項や約款を提示することで、調査コストを削減できます。
金融サービス:
ポリシー文書や市場レポートへの即時アクセスによって、顧客対応や内部判断のスピードを高めることが可能です。
教育機関・社内研修:
教材や社内規定をベースに、LLMと連動した質問応答システムを構築することで、学習効率の向上に貢献します。
コスト効率の良さ
従来のRAGアーキテクチャでは、ベクトルデータベースの構築・運用に一定の専門知識とインフラコストが必要でしたが、Amazon Bedrock Knowledge BasesとS3 Vectorsを使用することで、複雑な構成管理を排除し、データのアップロードからアプリケーション統合までをフルマネージドで実行できます。
加えて、従量課金型モデルであるため、小規模からのスモールスタートが可能で、アプリケーション規模の拡大に合わせて自然にスケーリングが行えます。これにより、実証実験から本番運用までの移行がスムーズに進行する点も魅力的です。
まとめ
Amazon Bedrock Knowledge BasesとS3 Vectorsを使用することで、最新のRAGアプリケーションを簡単かつコスト効率よく構築することが可能になりました。特に、内部文書などによるハルシネーションのリスク回避、ドメイン知識を反映した高品質な応答生成、さらにはインフラ運用の簡素化など多くのメリットがあります。
生成AIを活用したアプリケーションを開発・運用する企業にとって、このアプローチは実用性の高い選択肢となるでしょう。今後ますます増えるであろう非構造化データの活用を視野に入れながら、RAGアーキテクチャを基盤としたプロダクト開発や社内ツールの強化を図っていくことが期待されています。
今こそ、クラウドネイティブで拡張性に富んだRAGアプリケーションへの第一歩を踏み出す絶好の機会です。Amazonの最新サービスを活用し、より確実で信頼性の高いAI活用を目指してみてはいかがでしょうか。









