ディープラーニングが進化を続けるなかで、モデルのスケーラビリティと柔軟性はますます重要なトピックになっています。とりわけ、Transformerアーキテクチャは自然言語処理や画像認識、音声処理など、さまざまな領域で成果を上げていますが、その学習コストや更新の困難さは依然として課題として残っています。今回紹介する論文「Growing Transformers: Modular Composition and Layer-wise Expansion on a Frozen Substrate」は、既存のTransformerモデルを効果的に拡張するための新たなアプローチを提案しており、スケーラブルで効率的なモデル成長戦略に対する深い洞察を提供しています。
本記事ではこの研究の背景や提案手法、実験結果、そして今後の応用可能性について、わかりやすく解説していきます。難解な数式や専門用語には立ち入りすぎず、それでも本質的な価値や意味を伝えることを目指します。
Transformerとは何か:簡単なおさらい
Transformerは、文章などの系列データを高精度に処理するために発表されたアーキテクチャで、自己注意(Self-Attention)メカニズムにより、現在のAIの中核技術となっています。このTransformerはレイヤー(層)ごとに情報を処理するスタック構造となっており、各レイヤーがある特定の機能を果たすことで全体として高い表現力を持つように設計されています。
しかしその一方で、トレーニング済みのモデルをさらに大きくしたい場合や、既存の構造を改良したい場合に、一度すべてのパラメータを再学習しなければならないという制約が存在します。これは膨大な計算資源と時間を必要とするため、現実的な適用には限界がある場合も少なくありません。
問題提起:モデルの拡張はなぜ難しいのか
大規模な言語モデルや汎用AIモデルは日々進化していますが、その成長には大きなトレードオフが伴います。新たなタスクへの対応や性能向上を求めてネットワークの規模を拡大することは可能ですが、そのたびに既存のモデル全体を再トレーニングするのでは、コストと時間が膨大です。さらに、再学習中に過去の知識を失ったり(いわゆる忘却)するリスクもあります。
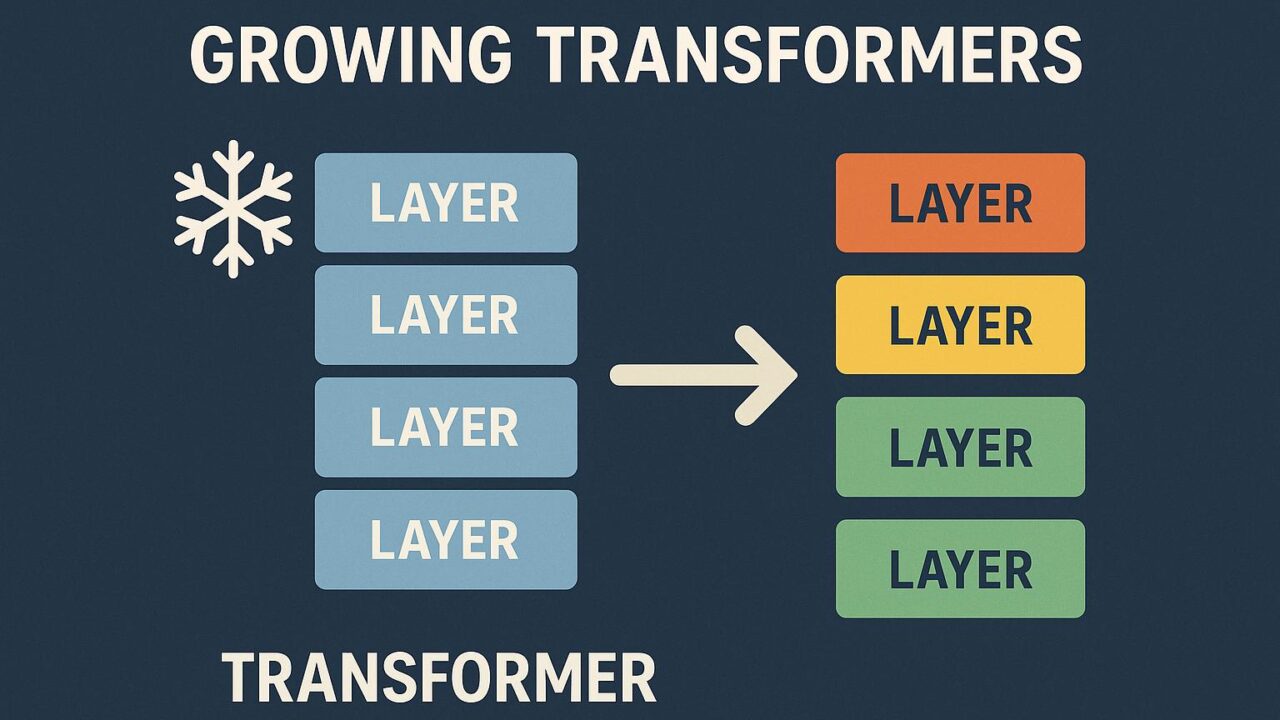
今回の論文では、こうした課題への解決策として“成長可能なTransformer(Growing Transformer)”というアプローチが提案されています。
Frozen Substrateという発想
本研究の核となるアイディアは、トレーニング済みのTransformerモデル(これを“Frozen Substrate”と呼びます)を固定したまま、その上に新たなレイヤーを追加していくというものです。この“Frozen”(凍結された)層はパラメータの更新を行わず、ただ機能を提供し続ける基盤となり、新たに追加されたレイヤーだけを訓練対象とします。
この仕組みにより、既存の知識を保持しながら新しい機能や表現力を獲得することが可能になります。また、すべてのパラメータを再訓練する必要がないため、効率的に新しいモデルを構築できるわけです。
Layer-wise Expansion:レイヤー単位の拡張
さらに、追加されるレイヤーは単にコピーしたものではなく、あらゆる構成が可能な“モジュール”として設計されています。これにより、各レイヤーが異なる働きを担えるようになり、より柔軟なネットワーク構造が実現されます。各層は特殊な設計も可能で、例えば他のモデルから移植されたレイヤーや、異なる形式のアテンションブロックなども組み込めます。
この構造の利点は、モデルの拡張や改良を段階的に行える点にあります。従来のようにすべてのネットワークパラメータを一度に変更せずとも、必要に応じて段階的にレイヤーを追加していけるため、メンテナンス性や再利用性にも優れているのです。
Modular Composition:モジュラー構成という柔軟性
もう一つの大きな特徴はモジュラー構成です。各レイヤーを一つの独立したモジュールとして捉えるこの発想は、機械学習モデルを部品として再利用可能にする考え方にもつながります。例えば、すでに構築した他のモデルから一部のレイヤーを流用したり、タスクに応じて特定のレイヤーのみを入れ替えることが可能になります。
このような柔軟性は、産業応用や研究開発の現場で非常に有効です。あるタスクで高い性能を示したレイヤーを他のタスクに活用することで、開発コストを抑えながら確実に精度を高めることができるからです。
実験と結果の概要
本研究では、上記の手法を実際の自然言語処理タスクに適用し、従来のトレーニング方法と性能や効率性を比較しています。たとえば、凍結層の上に数層の新レイヤーを追加したモデルでも、完全な再トレーニングを行った通常のモデルと同等以上の性能を示した用例があります。特に、特定の領域へのファインチューニングや新しいタスクへの適用において、非常に高い効率性が確認されています。
また、ドメイン適応や継続学習のようなシナリオでも、凍結層を活用することで旧モデルとの知識の橋渡しが可能となり、コンテキストを失わずに適応できる点が優れています。
このアプローチの意義と今後の可能性
Growing Transformersは、AIモデルの設計と学習において新たなパラダイムを提示するものであり、その意義は計り知れません。とくに、近年ではモデルサイズの限界や計算資源への懸念が高まっており、効率的な資源利用が求められています。Frozen Substrateの考え方は、これに対する一つの有力な回答といえるでしょう。
また、モジュラーかつレイヤー単位の成長構造という設計は、今後のAIモデルをより持続可能で、拡張性に富んだものへと進化させる可能性を秘めています。例えば、個別ユーザー向けにカスタマイズされたモデルや、特定業務に特化したモデルの効率的な生成も視野に入ってきます。
結びに:誰もが参加できる進化のステージへ
これまでのディープラーニングでは、大規模な計算資源を持つ一部の研究機関や企業に限られていたモデル開発が、Growing Transformersのようなアイディアにより徐々に“民主化”されつつあります。誰もが既存モデルの知識を再利用しながら、必要に応じてそれを改良・拡張できるという環境は、未来のAI開発にとって非常にポジティブな方向性です。
知識の継承と成長が両立するこの手法は、直線的な学習から循環的な進化へと、AI開発の新たなステージを切りひらいていくでしょう。その意味で、Growing Transformersはただの技術的ブレイクスルーではなく、より柔軟で開かれたAI開発の姿勢をも示しているといえます。
今後の展開にも注目しながら、この革新的なアプローチを様々な領域に活用していくことが期待されます。技術の進化は止まることなく、私たちの手でその可能性は無限に広がっていくのです。




