音声要約ソリューションをサーバーレスで構築する:Amazon BedrockとWhisperを用いた革新的アプローチ
近年、音声メディアの利用が飛躍的に伸びています。ビジネス会議、ポッドキャスト、オンライン講義、カスタマーサポート通話など、私たちは日々膨大な量の音声データに触れ、時には保存・共有する必要があります。しかし、これらの音声データの価値を引き出すためには、「要約」が鍵を握ります。
音声要約とは、長時間に及ぶ音声の内容を短時間で把握できるように要点を抽出する技術です。この技術により、ユーザーは必要な情報だけを迅速に得ることができます。特に、リモートワークの普及やカスタマーサポートの自動化が進む中、音声要約の需要は増す一方です。
本記事では、Amazon Web Services(AWS)の公式ブログにて紹介された「Amazon Bedrock」と「Whisper」を組み合わせた、サーバーレスな音声要約ソリューションの構築方法を紹介します。開発者にとっても、企業にとっても、革新性の高いこのアプローチは、スケーラブルかつ高精度な音声処理の実現を可能にします。
音声要約の課題と背景
音声要約の一般的な課題にはいくつかの側面があります。
– 音声認識技術の精度:さまざまなアクセント、話者の話し方、騒音などにより、音声認識が難しくなることがあります。
– 要約の品質:自動的なテキスト要約では、話の文脈や論理が失われやすく、ユーザーが必要としている情報が正確に抽出されない可能性があります。
– リアルタイム性とスケーラビリティ:大量の音声データを処理するには、効率的で拡張性のあるインフラストラクチャが必要です。
こうした課題を受けて、AWSは、最新の機械学習技術とサーバーレスアーキテクチャを活用し、柔軟かつ堅牢な音声要約ソリューションを提案しています。
Amazon BedrockとWhisperの役割
音声要約のプロセスは大まかに2段階に分かれます。
1. 音声認識(Transcription):音声データをテキストに変換
2. テキスト要約:得られた文字データを要約・整理
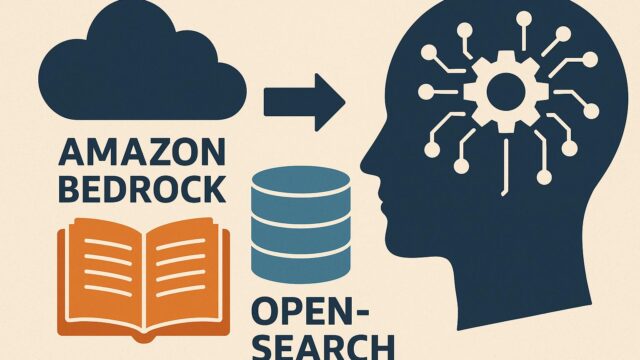
このプロセスにおいて、OpenAIが開発したWhisperモデルは音声認識に用いられます。一方、Amazon Bedrockは、テキスト要約に適した生成AIモデル(例:AnthropicのClaude、AI21 LabsのJurassic-2、Amazon Titanなど)にAPIベースでアクセスするためのマネージドサービスです。
Whisperは多言語対応かつ高精度な音声認識モデルとして定評があり、ノイズを含むファイルやさまざまな言語にも対応できます。このモデルは、PythonおよびHugging Faceライブラリを使ってラップされ、音声ファイルを素早くテキスト化します。
Amazon Bedrockの利点は、マネージドな形式で複数の生成AIモデルにアクセスできるため、インフラ管理なしで効果的な要約処理が可能になる点です。このAPIベースのアプローチにより、開発者はコーディングに集中でき、自動スケーリング・セキュリティ・運用管理について心配する必要がありません。
アーキテクチャの概要
AWSが提案するアーキテクチャはサーバーレスであり、以下のAWSサービスを中心に構成されています。
– Amazon S3:音声ファイルの保存場所
– AWS Lambda:音声ファイルをWhisperで処理し、Amazon Bedrockを呼び出すためのコンピューティング機能を提供
– Amazon Bedrock:テキスト要約処理
– Amazon API Gateway:外部アプリケーションとのインターフェース
– Amazon EventBridge:イベント駆動型の処理開始トリガー
– IAM(Identity and Access Management):厳格なアクセス制御
この構成により、ユーザーが音声ファイルをS3にアップロードすると、EventBridgeがアップロードイベントを監視し、Lambda関数を起動。Lambda内でWhisperにより音声ファイルが文字起こしされ、その出力がAmazon Bedrockに渡され要約されます。要約結果はさらにS3に格納されるか、必要に応じてエンドユーザーのアプリケーションに返されます。
コードサンプルとデモの流れ
AWS公式ブログでは、非常に親切なコード例が提供されています。Pythonベースで構築されたこのラッパーは、音声ファイルをWhisperに渡し、得られたテキストをAmazon Bedrockへ送信。エンドポイントからの応答として、高品質な要約が取得されます。
要点となるステップは以下です。
1. 音声ファイル(例:MP3形式)をAmazon S3に保存
2. Lambda関数がイベント駆動で起動
3. Whisperで音声ファイルを解析し文字起こし(英語など多言語対応可)
4. Lambdaで整形されたテキストをBedrockのAPIに渡す
5. 得られた要約テキストをS3に保存または別途処理
このプロセスはほぼリアルタイムで完結し、必要に応じて他のAWSサービス(通知やUI連携など)との連携も可能です。
サーバーレスの利点とは?
このソリューションにおける最大の魅力の一つは、完全にサーバーレスである点です。これにより、次のような利点が享受できます。
– 運用コストの削減:実行された処理単位で課金され、未使用時のリソース維持費が発生しません
– スケーラビリティ:高負荷時にも自動的にスケールアウト
– 可用性と耐障害性:AWSが提供するサーバレス基盤により高い冗長性
– メンテナンス不要:インフラのパッチ適用や更新は不要
これにより、スタートアップから大企業まで幅広い組織が、柔軟かつ迅速に音声処理と要約機能を導入できます。
活用例とユースケース
この技術はさまざまなシーンでの活用が想定されます。
– 会議録の自動作成と要約(例:Zoom録画音声の要約)
– カスタマーサポートの通話記録の分析
– 教育・Eラーニング用の講義音声の要約
– ポッドキャストやラジオのダイジェスト生成
– 医療現場における患者との会話の記録と要約
– ジャーナリズムや報道のインタビュー内容の素早い要点把握
これらのユースケースでは、効率化と時間短縮により、関係者の負担軽減や意思決定のスピード向上が期待できます。
まとめ:誰もが使えるインテリジェントな音声要約へ
AWSが提案するこの音声要約ソリューションは、先進的なAIモデル(WhisperとBedrock)をサーバーレス・アーキテクチャに統合することで、開発者や企業に対し、直感的でスケーラブル、しかも高パフォーマンスな解決策を提供しています。
インフラ構築の手間を最小限に抑えつつ、最新の生成AI技術を活用できるこのソリューションは、今後音声コンテンツがますます重要になる中で大きな可能性を秘めています。情報の取得スタイルが「読む」から「聞く」にシフトしてきた現代社会において、このような技術の存在は非常に価値があります。
業務の効率化を目指す開発者、ユーザー体験を向上させたい企業、あるいは日常生活にAIを取り入れたい個人にとって、この音声要約ソリューションは極めて有用なツールとなるでしょう。AWSとOpenAIによるこの取り組みは、誰もが簡単に使えるインテリジェントな音声処理の未来像を指し示しているのです。