産業分野における外観検査などの応用で「異常検知」は非常に重要な技術ですが、困難な面もあります。その最大の要因は、異常のサンプルが非常に少ないという点です。特に機械学習やディープラーニングを用いる異常検知モデルでは、正常なデータがたっぷりあっても、少しでも異常が現れるとそれをどう扱うかが課題となります。
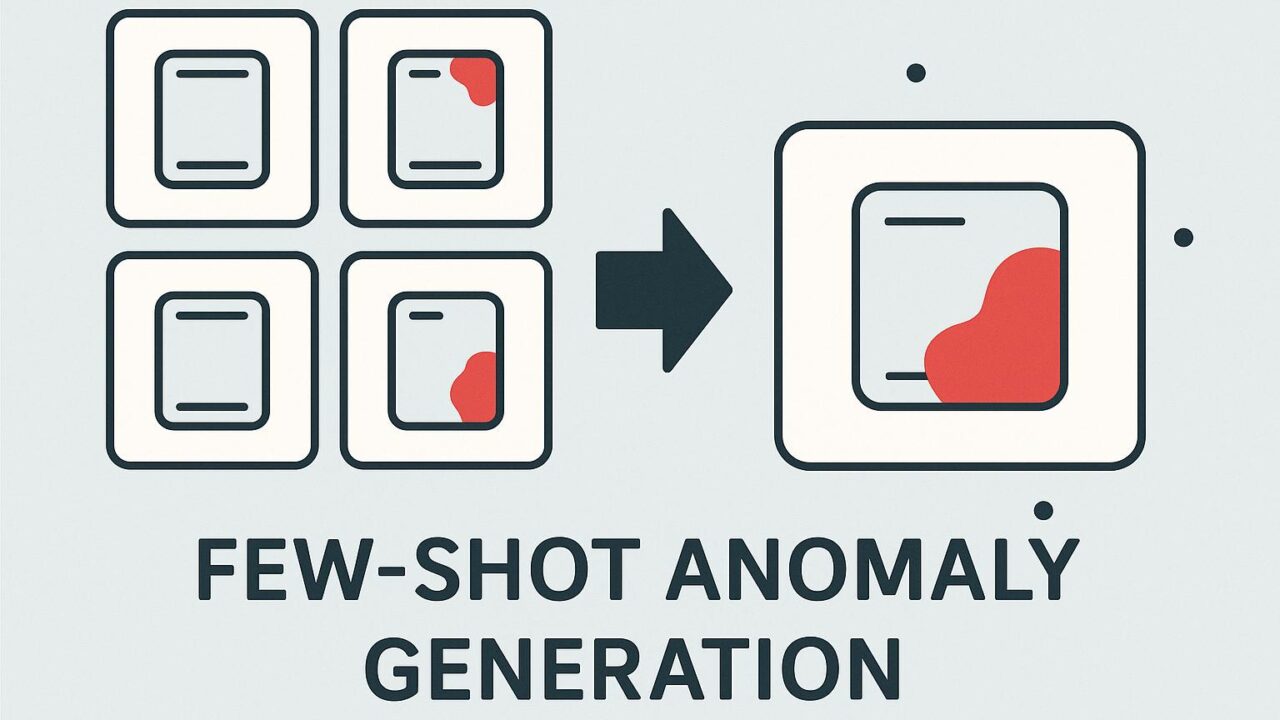
この記事では、そうした課題を解決するための新しい技術「AnoGen(Anomaly-driven Generation)」が紹介されています。これは「Few-Shot」と呼ばれる、学習用にごくわずかな実データしか必要としない手法の一つです。AnoGenの目的は、限られた数の本物の異常例から、リアルで多様な異常画像を生成し、それによって異常検知モデル全体の性能を高めようというものです。
以下、技術的な仕組みと意義についてわかりやすく解説します。
■ なぜ従来の人工異常では不十分なのか?
従来の方法では、ランダムなノイズを加えたり、外部から全く違うデータを加工して「偽の異常」を作る方法がとられてきました。しかし、こうしたデータは本当の現場で発生する異常とは明らかに見た目や意味が違います。これは「セマンティック・ギャップ(意味のずれ)」と呼ばれ、モデルに正しく異常を学習させるのを妨げてしまいます。
■ AnoGenの3つのステージ
AnoGenは3段階で異常データを生成します:
1. 異常の埋め込み学習(Anomaly Embedding Learning)
わずか数枚の実際の異常画像から、異常の概念や見た目を「特徴」として抽出し、ベクトル空間(埋め込み空間)に変換します。これが生成モデルの土台になります。
2. 生成モデルによる異常画像の生成(Diffusion-based Generation)
近年話題の「ディフュージョンモデル(拡散モデル)」を利用して、画像のノイズと情報を段階的に処理しながら、より現実らしい異常を特定の場所(例えば製品の一部)に生成します。ここでは、Bounding Box(異常を起こしたい場所の枠)も活用して、制御された異常生成が可能です。
3. 弱教師あり異常検知モデルの学習(Weakly-supervised Training)
最後に、こうして作られた人工異常画像を用いて異常検知モデルを改良します。完全なラベル付けがなくても学習できる「弱教師あり」方式を活用し、高精度な異常分類・異常セグメンテーションが実現されます。
■ 結果とベンチマーク評価の実績
この研究では、「MVTec AD」と呼ばれる有名な産業用異常検知データセットを使って評価が行われました。実験では、ベースモデルとして有名な「DRAEM」や「DesTSeg」を利用し、AnoGenで生成された異常画像を使うことで以下のようなパフォーマンス向上が確認されました:
– DRAEM:異常セグメンテーションで AU-PR(Precision-Recall曲線の面積)が5.8%改善
– DesTSeg:同様に1.5%改善
これらの数値は、生成された異常が非常に質が高く、現実の異常と見分けがつかないほどリアルであることを示しています。
■ 技術的なコメント:なぜディフュージョンモデルなのか?
最近の生成画像技術では、GAN(敵対的生成ネットワーク)よりも、より品質の高い画像生成が可能な「拡散モデル(ディフュージョンモデル)」が注目を集めています。この技術は、画像を一旦ノイズまみれにした後、少しずつ本来の画像へと復元していくステップを繰り返しながら学習するため、多様で自然なパターンを生成するのが得意です。AnoGenのように、異常という「普通でない模様」や「局所的な異変」を学ぶには、この拡散モデルの段階的な構築手法が適していると言えるでしょう。
■ まとめ:実用性と将来性
AnoGenは、実際に異常が発生しにくくデータが集まらないような産業現場で大活躍する可能性を秘めた技術です。さらに、生成画像の質の高さにより、異常のセグメンテーション(どこが異常かをピクセル単位で探す)といったより細かいタスクでも性能向上が確認されています。また、コードもGitHub(https://github.com/gaobb/AnoGen)で公開されており、誰でも試すことができます。
近年、AI技術において「データの質と多様性」がますます重要になってきています。特に異常検知の分野では、「数少ない真実から、確かなモデルを構築する」ことがまさに求められています。AnoGenはまさにこの課題に対して一石を投じた、非常に意義深い技術革新だと言えるでしょう。