3次元ジオメトリを活用した高精度マッチング技術「LiftFeat」とは — 視覚認識の新たな一歩
ロボティクスや拡張現実 (AR)、自律走行車など、カメラを用いた視覚的な位置推定や空間マッピングには「ローカル・特徴マッチング(Local Feature Matching)」が欠かせません。これは、画像内の特徴点を検出し、それらを別の画像と比較・対応付ける技術で、自己位置の推定や空間構造の推定に使われます。
しかし、現在でも解決が難しい問題がいくつかあります。例えば、薄暗い場所や極端な明るさ変化、壁のように単調でテクスチャが乏しい領域、また同じパターンが繰り返されるような場所では、従来の2次元だけの特徴量ではうまくマッチングできないことがあるのです。
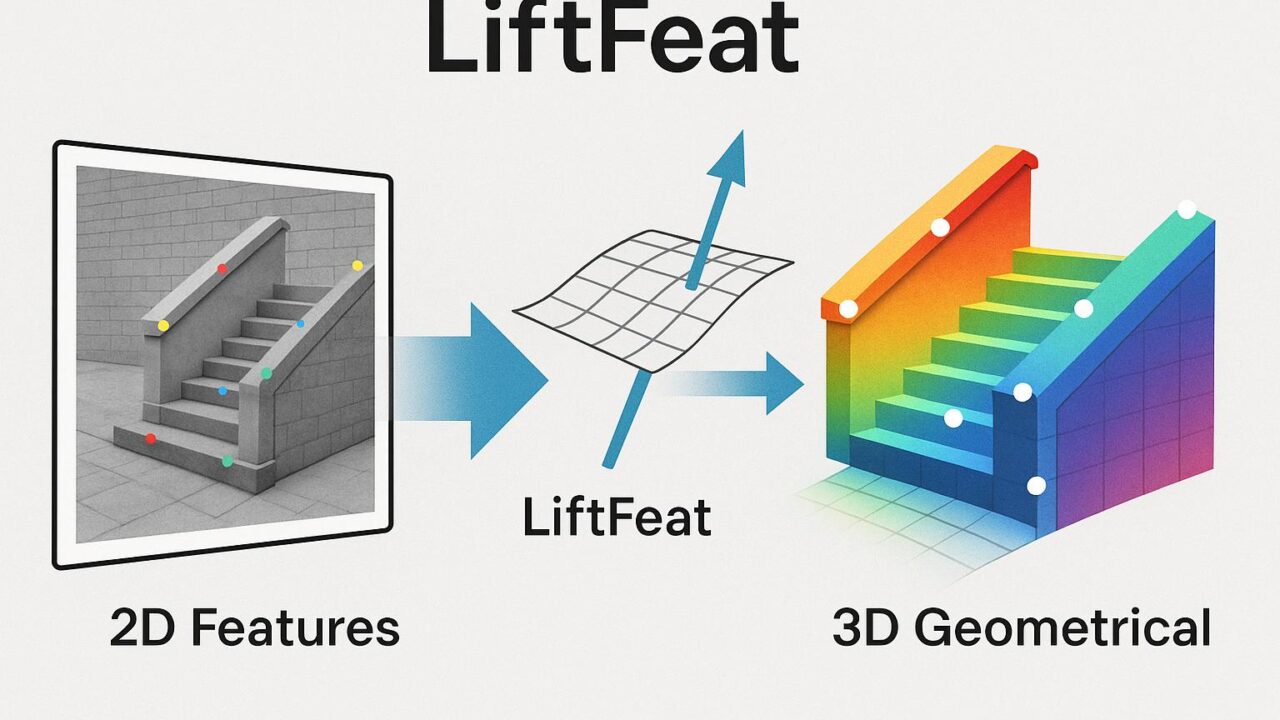
そんな中で、新たに誕生したのが「LiftFeat(リフトフィート)」という新しいローカル・マッチング手法です。本手法は、2D画像の特徴だけでなく、画像から推定された3D幾何情報、特に「サーフェスノーマル(表面法線)」を融合することで、特徴点の識別能力を大幅に高めています。
技術的な仕組み:2Dから3Dへ「持ち上げる」アプローチ
LiftFeatの核心は、これまでの平面画像上の処理にとどまらず、「2D特徴量を3D幾何特徴で補強する(リフトする)」という点にあります。以下のような手順で構成されています。
1. 単眼深度推定による擬似的な3D情報の導出
まず、既存の学習済みの「単眼深度推定モデル」(1枚の画像から深度を算出するモデル)を活用し、画像中の各ピクセルが向いている方向を示す「表面法線(Surface Normal)」を求めます。これが、シーンの3D的な構造をある程度再現する「擬似的な3Dラベル」になります。
2. 2D特徴との融合:ジオメトリアウェアな特徴リフティング
ここが最大の革新です。LiftFeatでは、「Feature Lifting Module(特徴リフティングモジュール)」という新たな処理ブロックを設け、上記の3D表面法線を、従来の2D画像特徴と統合します。これにより、画像の一部分が他と似ていても、視点的に異なる方向を向いていれば別の特徴として識別でき、より強靭で識別しやすいマッチングが実現できます。
これにより、従来の2Dだけでは判別が難しかった「似たような見た目だけれど向きが違う箇所」や、「薄い陰影の変化があるだけの平坦な場所」でも、有効なマッチングが可能になるのです。
実験でも明らかだったLiftFeatの優位性
LiftFeatは、自己位置推定や画像アライメント(変換推定)、さらには視覚ベースのローカライゼーションタスクにおけるベンチマークにおいて、他の軽量かつ最先端な手法と比較しても優れた性能を示しました。
中でも特筆すべきは、次の3点です。
– 視覚ローカライゼーションの精度向上:位置推定精度が高まり、特にロボットやドローンナビゲーションでの利用価値が高い。
– ロバスト性の向上:明るさの急激な変化や、単調なテクスチャでも正確に特徴をマッチできる。
– 計算リソースの効率的利用:ネットワーク全体が軽量に設計されており、リアルタイム動作や組み込みデバイスへの応用にも適している。
技術観点からの評価と今後の可能性
従来のローカルマッチングは「視覚情報=見た目」での比較が前提でした。しかし、実世界の物体や風景には「立体的な形」や「表面の向き」があり、人間の目と脳はこれらを自然と統合して理解しています。
LiftFeatのアイディアは、こうした「人間の空間認識に近い処理を画像認識にも導入しよう」とする試みであり、極めて論理的で自然です。しかも、「奥行き推定」と「特徴マッチング」を別モデルにすることで、既存の深度推定の技術をうまく組み合わせている点も非常にスマートです。
今後、この技術が進化することで、以下のような応用が現実的に期待できます:
– モバイルデバイス上で使えるARアプリの精度向上
– 安価なカメラしか搭載できないロボットへの精密な視覚ナビゲーション機能の搭載
– ドローンや無人車両の低照度環境下での安定した自己位置推定
まとめ
LiftFeatは、画像認識の問題に「3次元幾何」という新しい視点を巧妙に取り入れ、従来難しかった場面でも高信頼なマッチングを実現しました。まだ研究中の技術ですが、実用化へのハードルは低く、将来の視覚ローカライゼーションの標準技術の一つになる可能性を秘めています。
プロジェクトの詳細とコードは以下で公開されていますので、興味ある方はぜひチェックしてみてください:
https://github.com/lyp-deeplearning/LiftFeat