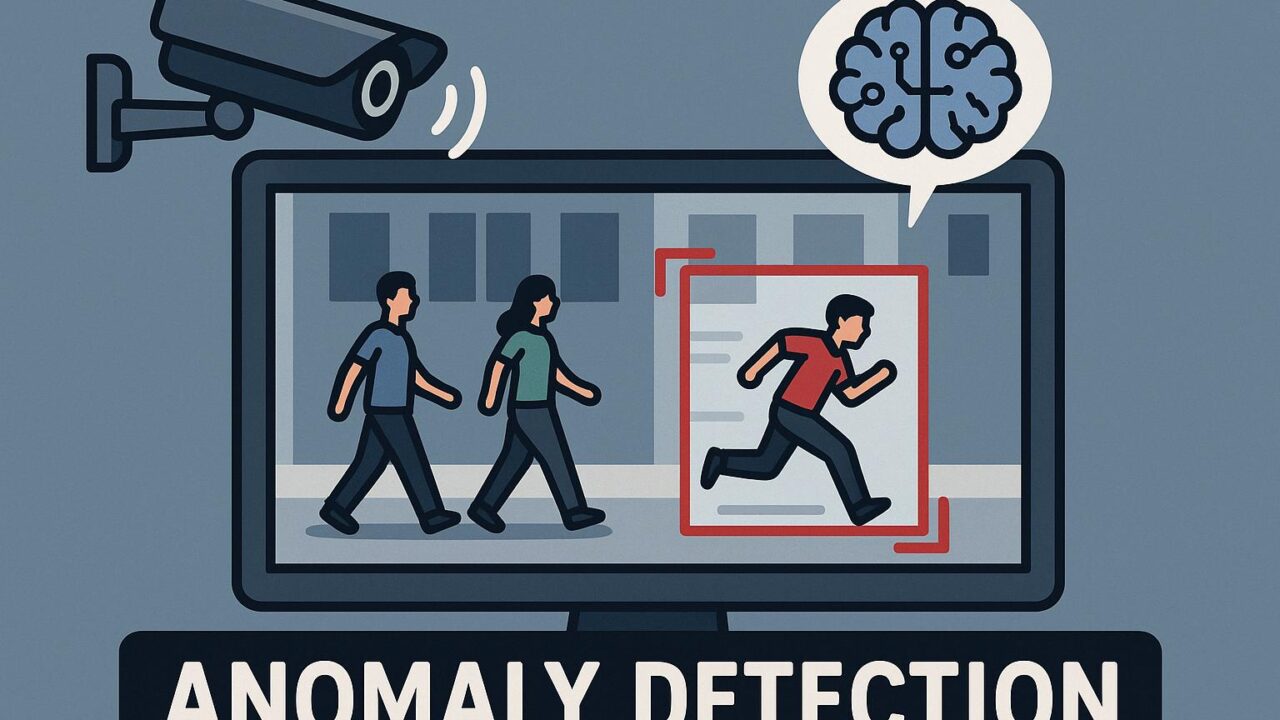
近年、監視カメラ映像や交通監視などにおける「異常検知(Anomaly Detection)」は、AIによる自動化の分野で重要な課題とされています。特に何千時間にも及ぶ映像を人間の目で確認することは現実的ではないため、ビデオから異常行動を検出する技術の進化が求められています。
このような背景の中で発表された研究「Uncertainty-Weighted Image-Event Multimodal Fusion for Video Anomaly Detection(IEF-VAD)」は、既存の方式と一線を画す先進的なアプローチを提案しています。本記事では、この手法の技術的特徴をやさしく、かつ詳細に解説します。
■ 従来の課題:RGB画像だけでは「一瞬の異常」に弱い
現在多くの異常検出システムは、映像を構成するRGBフレームのみを入力として解析しています。しかしこの方式では、突発的な動きや一瞬の変化といった「異常の兆候」が十分に捉えきれません。
例えば、誰かが急に走り出す、落下物が発生するといったイベントは、ほとんどのフレームでは目立たない「一瞬の変化」に過ぎないため、動きの情報が弱いRGB画像だけでは抽出が困難なのです。
■ 解決策:RGB映像から「イベント表現」を合成して融合
IEF-VADはこの問題に対処するため、専用のイベントカメラを使わずとも、RGB映像から「イベント情報(動きのエッセンス)」を合成できる技術を提案しています。
一般的に「イベントカメラ」では、動きの変化だけを時間的に非常に高解像度で捉えられますが、高価で汎用性に欠けます。IEF-VADでは、通常のRGB映像に対して機械学習的にイベント情報を疑似的に再現(synthetic event representations)し、RGBフレームの情報と「融合」することで、動きの特徴を強く捉える異常検知を可能にしています。
この融合処理は単純な足し算ではなく、以下のような高度な数理的枠組みを用いています。
■ 3つの技術的特徴:不確実性、逐次更新、残差除去
IEF-VADには技術的に注目すべき3つの工夫があります。
① 不確実性に基づく重み付け(Uncertainty-Weighted Fusion)
現実の映像には様々なノイズ(センサーの感度、光のちらつき、シャドウなど)が含まれ、不確実性が付きまといます。IEF-VADでは、センサーのノイズが「重い裾(heavy-tailed)」を持つという前提に基づき、Student’s-t分布という統計的分布を用いることで、ノイズの影響を数理的にモデル化。
その上で、Laplace近似という確率推論手法を使い、RGB画像・合成イベント表現それぞれの信頼性(逆分散)を求め、その信頼度に応じて重みを変える「不確実性認識型融合」を行います。つまり、どちらの情報がより信頼できるかを動的に判断して、融合の度合いを調整します。
② カルマンフィルタ風の逐次的な融合更新
映像は時間と共に進みます。IEF-VADでは、「今の瞬間」だけでなく、「過去からの経緯」を重視して融合情報を更新します。
これは、状態推定で有名な「カルマンフィルター」に着想を得た手法で、フレームごとにRGBとイベントそれぞれの情報を取り込みながら、時系列的に状態を推定・更新していきます。これにより、単発的な誤検出を抑えつつ、連続動作の中での異常にも対応可能になっています。
③ 融合後の「残差ノイズ」をさらに正す
たとえ融合がうまくいっても、RGBとイベント表現の間には微妙なギャップ(ノイズ)が残る可能性があります。IEF-VADでは、一度融合した潜在表現に対して繰り返し「残差誤差」を精査・修正するプロセス(iterative refinement)を導入。この再洗練により、異なるモダリティ間で発生しやすいノイズやズレを最小限に抑えています。
■ 実験成果:複数の異常検出ベンチマークで最先端性能
IEF-VADは、専用のイベントカメラやすでにラベル付けされたフレームを使わずに、多くのビデオ異常検出ベンチマーク(ShanghaiTech、UCF-Crimeなど)で新たな最先端精度(state-of-the-art)を記録しています。
これはつまり、特別なハードウェアも、高価な事前アノテーションも不要で、現実の防犯監視・交通監視などへの導入が現実的に近づいたことを意味します。
■ 技術的なインパクトと今後の展望
IEF-VADの最大の意義は、「普通のRGB映像だけを使って、動きに強い異常検知ができる」と立証した点にあります。
イベント表現を自前で合成し、その中のノイズや信頼度まで数理的に扱える手法は、将来のあらゆるマルチモーダル映像理解に応用可能です。監視、ドローン、ロボットナビゲーション、自動運転など、瞬間的な動きが命取りになる分野との相性も抜群です。
さらに、本研究はGitHub上でコードと学習済みモデルが公開されており、誰でも再現や改良が可能です。(https://github.com/EavnJeong/IEF-VAD)
■ おわりに:融合技術がひらく映像AIの新章
RGBの画像情報だけでは見逃されていた「一瞬の異常」を、数字や物理的モデルで捉え直し、融合する――IEF-VADは、まさに今後の映像AIの可能性を切り拓く技術だといえます。
専門的な数理モデルを使いつつも、その目的は「人間では見極めにくい異常を、AIが賢く補完すること」。すべてのカメラが高性能センサーを搭載する時代ではなくとも、既存のデバイスと映像だけで高性能な異常検知が可能になる。この発想は、技術と社会を結ぶうえでも非常に重要です。