ロボティクスにおける視覚モデルの進化:Pollen-Visionがもたらす未来
近年の人工知能技術、特に深層学習の発展により、視覚認識技術は驚異的な進化を遂げてきました。画像認識・物体検出・シーン理解といった従来のタスクにおいて、AIモデルは人間と同等、あるいはそれを超える性能を発揮するようになっています。こうした技術は医療・製造・自動運転・農業など幅広い分野で応用されており、特にロボティクスにおいては視覚情報の処理能力がロボット自身の知覚と行動決定に直結するため、非常に重要な役割を果たします。
しかしながら、実際のロボティクス応用においては、複数の視覚モデルやツールを目的・シーンごとに使い分ける必要があるという複雑性が存在していました。こうしたユースケースごとのモデル切り替えやAPIの統一性の欠如は、開発を難しくし、スケーラブルなロボティクス視覚システムの実装を妨げる要因となっていました。
この課題に対し、Hugging Faceが発表したのが「Pollen-Vision」と名付けられたソリューションです。Pollen-Visionは、ゼロショット(Zero-Shot)視覚モデルをロボティクス領域に簡単に統合できるようにするための、統一インターフェースを提供するPythonライブラリです。この記事では、Pollen-Visionがもたらす変化、技術的背景、今後の応用可能性について詳しくご紹介していきます。
Pollen-Visionとは何か?
Pollen-Visionは、複数の先進的なゼロショットビジュアルモデルを、共通のインターフェース上で利用できるようにすることを目的としたライブラリです。たとえば、OpenAIのCLIPやMetaのSegment Anything Model (SAM)、GroundingDINOなど、自然言語プロンプトをベースにした視覚的タスクを処理できるモデルに対応しています。
Pollen-Visionの利用者は、複雑な個別APIや異なるフォーマットに頭を悩ませることなく、Pythonのシンプルなコードで高度な視覚認識や視覚に基づく意思決定を行うことができるようになっています。これは特に、ロボットが未知の環境において柔軟に行動することを求められるタスク(例:物体の探索や操作)において、大きな力を発揮します。
なぜ「ゼロショット」が重要なのか?
従来のコンピュータビジョンモデルやロボットに搭載される視覚認識システムは、事前に学習した対象に対してしか高精度で認識が出来ないという制約がありました。つまり、新しいオブジェクトや環境に対応するためには、その都度データを集めて再学習させる必要があり、非常にコストがかかります。
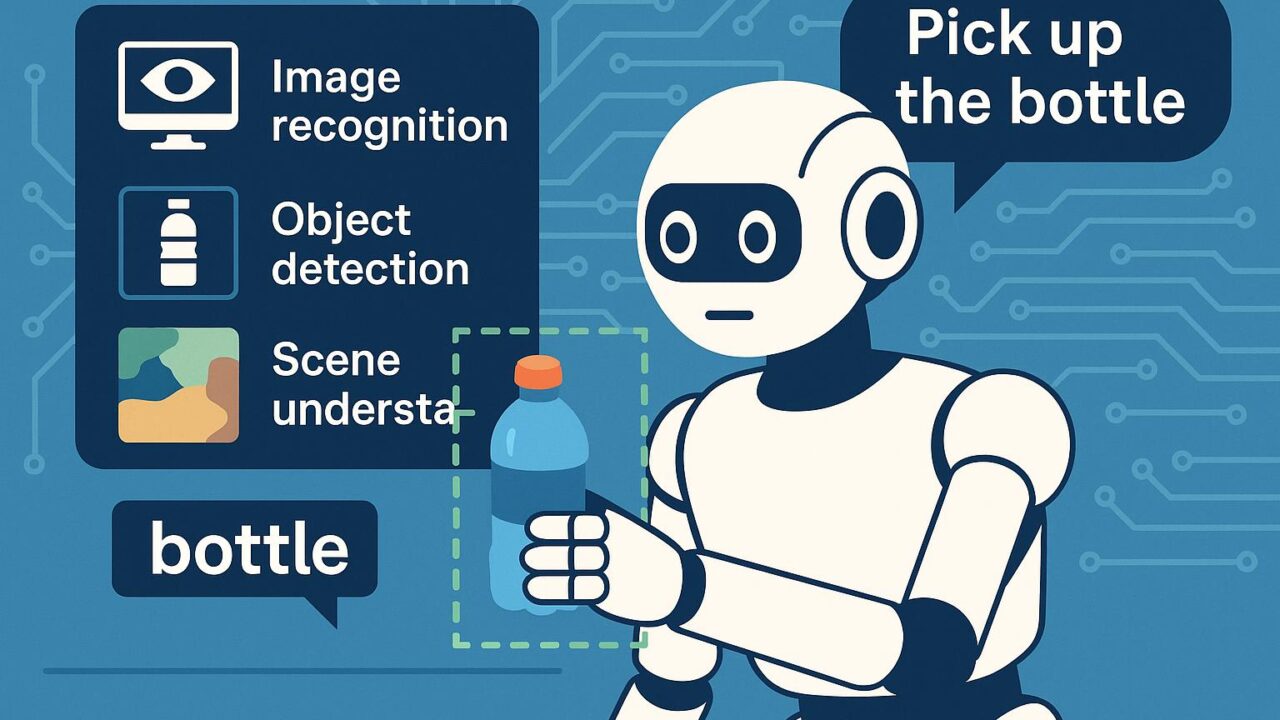
一方でゼロショット学習(Zero-Shot Learning)では、あらかじめ学習されていないタスクやオブジェクトに対しても、自然言語ベースの記述を用いて推論・認識を行うことができます。これにより、ロボットに「赤いボトルを探して取ってきて」と命令するだけで、明示的に赤いボトルを画像データで学習させていなくとも、視覚モデルが文理解と画像認識を組み合わせて目的の行動を実現することが可能になります。
この技術的飛躍により、ロボットの汎用性は格段に向上します。また、あらゆる場面での即時的な対応が可能となり、社会実装の幅も格段に広がります。
シンプルかつ強力なインターフェース
Pollen-Visionは使いやすさを第一に設計されています。主要なモデルを1つの統一されたフレームワーク上で利用できるという設計により、プログラマや研究者は個別のドキュメントや依存解決に煩わされることなく、高機能な視覚処理タスクを組み込むことができます。
例えば、Segment Anything Model (SAM) を活用して画像中の任意の部分を自然言語プロンプトで指定し、該当部分をマスクとして抽出するといった処理も数行のコードで実現可能です。このようなことが可能になることで、プロトタイプから実動作ロボットへの転用が容易になり、開発の高速化と信頼性向上へと繋がります。
また、Pollen-VisionはROS(Robot Operating System)との統合を念頭に置いており、多くのロボティクスプラットフォームとの連携が容易になっています。これは、現場で使われている実際のロボットへの導入という点でも、大きなアドバンテージとなります。
デモンストレーションと実用例
Pollen-Visionが実際にどのように活用できるのか——それを最も分かりやすく示しているのが、公式ブログで紹介されているデモ動画です。そこでは、ロボットが人間の音声命令に従って部屋から特定のオブジェクト(例:「水のボトル」)を識別して操作し、移動させる様子が確認できます。
この一連のタスクは、CLIPによる画像とテキストの意味的照合、GroundingDINOによる物体検出、SAMによるセグメンテーションといった複数のモデルを組み合わせて実現されています。そして、それらの複雑な組み合わせがPollen-Visionのシンプルなコードと統一インターフェースによって簡潔に実装されている点が、非常に印象的です。
将来的な展望とコミュニティの貢献
Pollen-Visionはまだ始まったばかりのプロジェクトですが、その構想と実装哲学は広く多くの開発者・研究者から注目を集めています。オープンソースとしてGitHub上にコードが公開されており、誰でも簡単に自分のプロジェクトに組み込むことができます。また、今後はより多くのモデルへの対応や、ROSとのシームレスな統合、スマートフォンやエッジデバイスへの最適化も検討されています。
さらに、コミュニティ主導のアップデートや機能追加も積極的に歓迎されており、今後数年でリアルタイムなマルチモーダル対話や、物理操作を伴う複雑タスクの自動化といった可能性も現実味を帯びてきています。
まとめ:ロボティクスの民主化を加速する
Pollen-Visionの登場は、ロボットの視覚能力を飛躍的に高めるとともに、専門的な知識がなくても先進的なビジュアルAIモデルにアクセスできる環境を整えるという点で、非常に意義深いものです。ゼロショット学習の応用によって、ロボットはより柔軟かつ直感的に人間の指示に反応できるようになり、日常生活や災害対応、医療現場などでの実装がより現実味を増しています。
技術の進歩とともに、人と機械のコラボレーションの可能性は広がっています。このような取り組みが、より分かりやすく、より使いやすくなることで、多くの人々にとってテクノロジーが身近なものとなる未来が期待されます。
Pollen-Visionは、ロボティクスの民主化を加速させる鍵の一つとなる、希望に満ちたステップであると言えるでしょう。興味がある方は、ぜひ公式ページやGitHubリポジトリをチェックし、その可能性に触れてみてください。
参考:
https://huggingface.co/blog/pollen-vision
GitHub: https://github.com/huggingface/pollen-vision